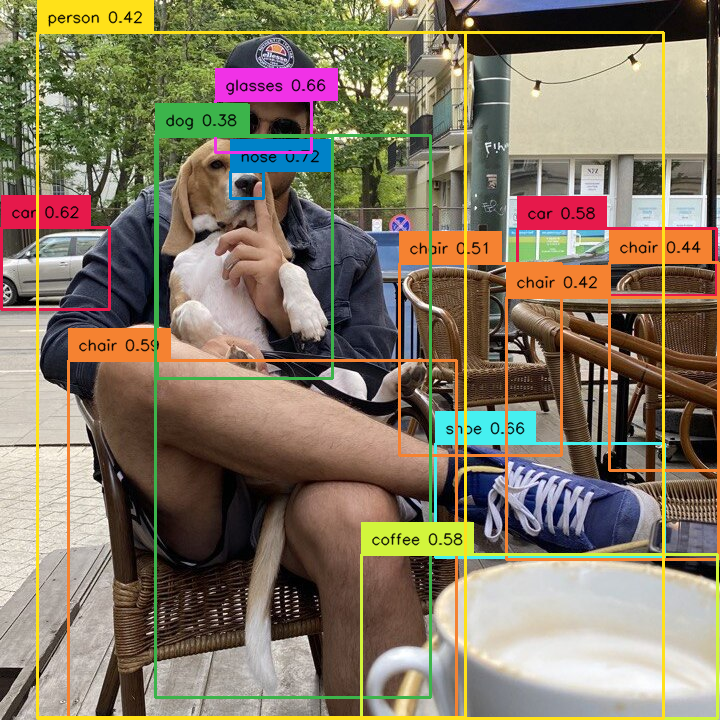
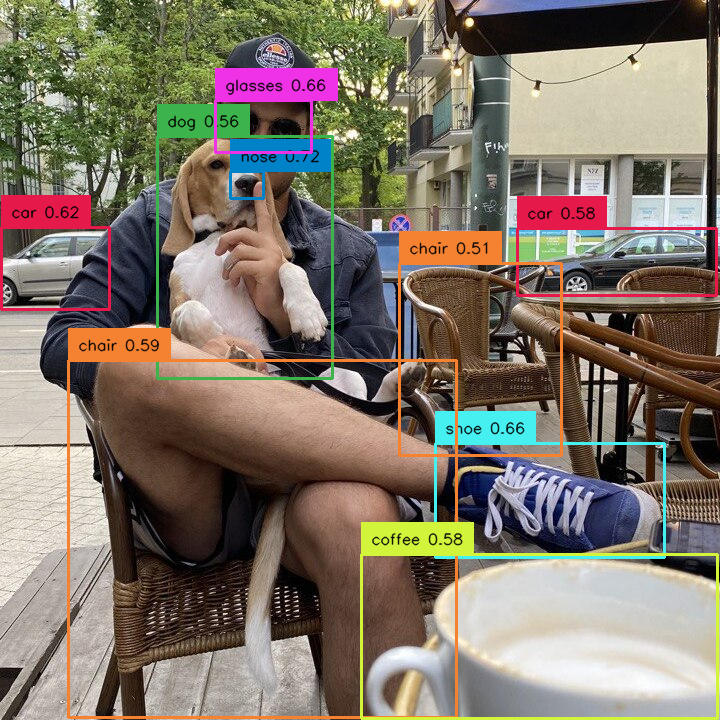
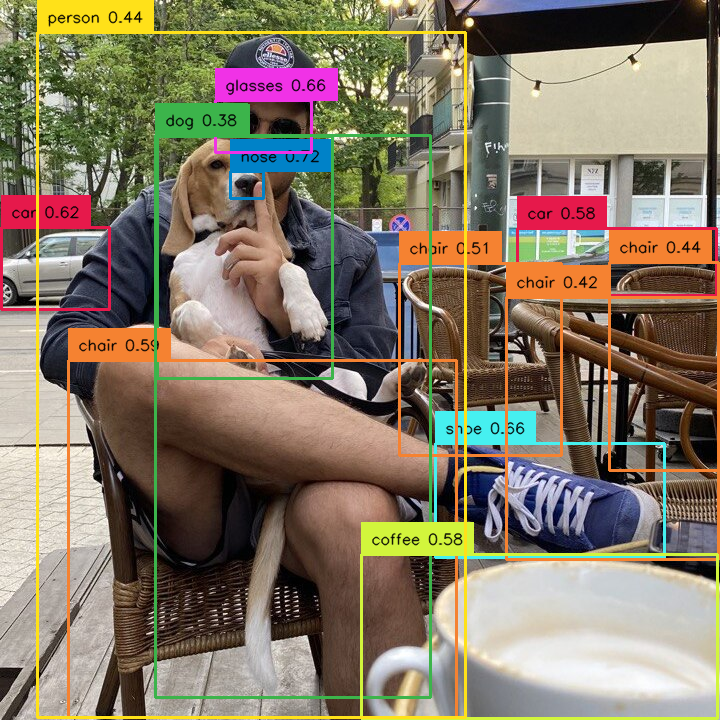
Added [#101]: ability to extract masks from YOLOv8 result using sv.Detections.from_yolov8. Here is an example illustrating how to extract boolean masks from the result of the YOLOv8 model inference.
+
+
+
Added [#122]: ability to crop image using sv.crop. Here is an example showing how to get a separate crop for each detection in sv.Detections.
+
+
+
Added [#120]: ability to conveniently save multiple images into directory using sv.ImageSink. Here is an example showing how to save every tenth video frame as a separate image.
Fixed [#106]: inconvenient handling of sv.PolygonZone coordinates. Now sv.PolygonZone accepts coordinates in the form of [[x1, y1], [x2, y2], ...] that can be both integers and floats.
Added [#100]: support for dataset inheritance. The current Dataset got renamed to DetectionDataset. Now DetectionDataset inherits from BaseDataset. This change was made to enforce the future consistency of APIs of different types of computer vision datasets.
defget_top_k(self,k:int)->Tuple[np.ndarray,np.ndarray]:
+"""
+ Retrieve the top k class IDs and confidences, ordered in descending order by confidence.
+
+ Args:
+ k (int): The number of top class IDs and confidences to retrieve.
+
+ Returns:
+ Tuple[np.ndarray, np.ndarray]: A tuple containing the top k class IDs and confidences.
+
+ Example:
+ ```python
+ >>> import supervision as sv
+
+ >>> classifications = sv.Classifications(...)
+
+ >>> classifications.get_top_k(1)
+
+ (array([1]), array([0.9]))
+ ```
+ """
+ ifself.confidenceisNone:
+ raiseValueError("top_k could not be calculated, confidence is None")
+
+ order=np.argsort(self.confidence)[::-1]
+ top_k_order=order[:k]
+ top_k_class_id=self.class_id[top_k_order]
+ top_k_confidence=self.confidence[top_k_order]
+
+ returntop_k_class_id,top_k_confidence
+
Dataset API is still fluid and may change. If you use Dataset API in your project until further notice, freeze the
+supervision version in your requirements.txt or setup.py.
@dataclass
+classDetectionDataset(BaseDataset):
+"""
+ Dataclass containing information about object detection dataset.
+
+ Attributes:
+ classes (List[str]): List containing dataset class names.
+ images (Dict[str, np.ndarray]): Dictionary mapping image name to image.
+ annotations (Dict[str, Detections]): Dictionary mapping image name to annotations.
+ """
+
+ classes:List[str]
+ images:Dict[str,np.ndarray]
+ annotations:Dict[str,Detections]
+
+ def__len__(self)->int:
+"""
+ Return the number of images in the dataset.
+
+ Returns:
+ int: The number of images.
+ """
+ returnlen(self.images)
+
+ def__iter__(self)->Iterator[Tuple[str,np.ndarray,Detections]]:
+"""
+ Iterate over the images and annotations in the dataset.
+
+ Yields:
+ Iterator[Tuple[str, np.ndarray, Detections]]: An iterator that yields tuples containing the image name,
+ the image data, and its corresponding annotation.
+ """
+ forimage_name,imageinself.images.items():
+ yieldimage_name,image,self.annotations.get(image_name,None)
+
+ defsplit(
+ self,split_ratio=0.8,random_state=None,shuffle:bool=True
+ )->Tuple[DetectionDataset,DetectionDataset]:
+"""
+ Splits the dataset into two parts (training and testing) using the provided split_ratio.
+
+ Args:
+ split_ratio (float, optional): The ratio of the training set to the entire dataset.
+ random_state (int, optional): The seed for the random number generator. This is used for reproducibility.
+ shuffle (bool, optional): Whether to shuffle the data before splitting.
+
+ Returns:
+ Tuple[DetectionDataset, DetectionDataset]: A tuple containing the training and testing datasets.
+
+ Example:
+ ```python
+ >>> import supervision as sv
+
+ >>> ds = sv.DetectionDataset(...)
+ >>> train_ds, test_ds = ds.split(split_ratio=0.7, random_state=42, shuffle=True)
+ >>> len(train_ds), len(test_ds)
+ (700, 300)
+ ```
+ """
+
+ image_names=list(self.images.keys())
+ train_names,test_names=train_test_split(
+ data=image_names,
+ train_ratio=split_ratio,
+ random_state=random_state,
+ shuffle=shuffle,
+ )
+
+ train_dataset=DetectionDataset(
+ classes=self.classes,
+ images={name:self.images[name]fornameintrain_names},
+ annotations={name:self.annotations[name]fornameintrain_names},
+ )
+ test_dataset=DetectionDataset(
+ classes=self.classes,
+ images={name:self.images[name]fornameintest_names},
+ annotations={name:self.annotations[name]fornameintest_names},
+ )
+ returntrain_dataset,test_dataset
+
+ defas_pascal_voc(
+ self,
+ images_directory_path:Optional[str]=None,
+ annotations_directory_path:Optional[str]=None,
+ min_image_area_percentage:float=0.0,
+ max_image_area_percentage:float=1.0,
+ approximation_percentage:float=0.0,
+ )->None:
+"""
+ Exports the dataset to PASCAL VOC format. This method saves the images and their corresponding annotations in
+ PASCAL VOC format, which consists of XML files. The method allows filtering the detections based on their area
+ percentage.
+
+ Args:
+ images_directory_path (Optional[str]): The path to the directory where the images should be saved.
+ If not provided, images will not be saved.
+ annotations_directory_path (Optional[str]): The path to the directory where the annotations in
+ PASCAL VOC format should be saved. If not provided, annotations will not be saved.
+ min_image_area_percentage (float): The minimum percentage of detection area relative to
+ the image area for a detection to be included.
+ max_image_area_percentage (float): The maximum percentage of detection area relative to
+ the image area for a detection to be included.
+ approximation_percentage (float): The percentage of polygon points to be removed from the input polygon, in the range [0, 1).
+ """
+ ifimages_directory_path:
+ images_path=Path(images_directory_path)
+ images_path.mkdir(parents=True,exist_ok=True)
+
+ ifannotations_directory_path:
+ annotations_path=Path(annotations_directory_path)
+ annotations_path.mkdir(parents=True,exist_ok=True)
+
+ forimage_name,imageinself.images.items():
+ detections=self.annotations[image_name]
+
+ ifimages_directory_path:
+ cv2.imwrite(str(images_path/image_name),image)
+
+ ifannotations_directory_path:
+ annotation_name=Path(image_name).stem
+ pascal_voc_xml=detections_to_pascal_voc(
+ detections=detections,
+ classes=self.classes,
+ filename=image_name,
+ image_shape=image.shape,
+ min_image_area_percentage=min_image_area_percentage,
+ max_image_area_percentage=max_image_area_percentage,
+ approximation_percentage=approximation_percentage,
+ )
+
+ withopen(annotations_path/f"{annotation_name}.xml","w")asf:
+ f.write(pascal_voc_xml)
+
+ @classmethod
+ deffrom_pascal_voc(
+ cls,images_directory_path:str,annotations_directory_path:str
+ )->DetectionDataset:
+"""
+ Creates a Dataset instance from PASCAL VOC formatted data.
+
+ Args:
+ images_directory_path (str): The path to the directory containing the images.
+ annotations_directory_path (str): The path to the directory containing the PASCAL VOC XML annotations.
+
+ Returns:
+ DetectionDataset: A DetectionDataset instance containing the loaded images and annotations.
+
+ Example:
+ ```python
+ >>> import roboflow
+ >>> from roboflow import Roboflow
+ >>> import supervision as sv
+
+ >>> roboflow.login()
+
+ >>> rf = Roboflow()
+
+ >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)
+ >>> dataset = project.version(PROJECT_VERSION).download("voc")
+
+ >>> ds = sv.DetectionDataset.from_yolo(
+ ... images_directory_path=f"{dataset.location}/train/images",
+ ... annotations_directory_path=f"{dataset.location}/train/labels"
+ ... )
+
+ >>> ds.classes
+ ['dog', 'person']
+ ```
+ """
+ image_paths=list_files_with_extensions(
+ directory=images_directory_path,extensions=["jpg","jpeg","png"]
+ )
+ annotation_paths=list_files_with_extensions(
+ directory=annotations_directory_path,extensions=["xml"]
+ )
+
+ raw_annotations:List[Tuple[str,Detections,List[str]]]=[
+ load_pascal_voc_annotations(annotation_path=str(annotation_path))
+ forannotation_pathinannotation_paths
+ ]
+
+ classes=[]
+ forannotationinraw_annotations:
+ classes.extend(annotation[2])
+ classes=list(set(classes))
+
+ forannotationinraw_annotations:
+ class_id=[classes.index(class_name)forclass_nameinannotation[2]]
+ annotation[1].class_id=np.array(class_id)
+
+ images={
+ image_path.name:cv2.imread(str(image_path))forimage_pathinimage_paths
+ }
+
+ annotations={
+ image_name:detectionsforimage_name,detections,_inraw_annotations
+ }
+ returnDetectionDataset(classes=classes,images=images,annotations=annotations)
+
+ @classmethod
+ deffrom_yolo(
+ cls,
+ images_directory_path:str,
+ annotations_directory_path:str,
+ data_yaml_path:str,
+ force_masks:bool=False,
+ )->DetectionDataset:
+"""
+ Creates a Dataset instance from YOLO formatted data.
+
+ Args:
+ images_directory_path (str): The path to the directory containing the images.
+ annotations_directory_path (str): The path to the directory containing the YOLO annotation files.
+ data_yaml_path (str): The path to the data YAML file containing class information.
+ force_masks (bool, optional): If True, forces masks to be loaded for all annotations, regardless of whether they are present.
+
+ Returns:
+ DetectionDataset: A DetectionDataset instance containing the loaded images and annotations.
+
+ Example:
+ ```python
+ >>> import roboflow
+ >>> from roboflow import Roboflow
+ >>> import supervision as sv
+
+ >>> roboflow.login()
+
+ >>> rf = Roboflow()
+
+ >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)
+ >>> dataset = project.version(PROJECT_VERSION).download("yolov5")
+
+ >>> ds = sv.DetectionDataset.from_yolo(
+ ... images_directory_path=f"{dataset.location}/train/images",
+ ... annotations_directory_path=f"{dataset.location}/train/labels",
+ ... data_yaml_path=f"{dataset.location}/data.yaml"
+ ... )
+
+ >>> ds.classes
+ ['dog', 'person']
+ ```
+ """
+ classes,images,annotations=load_yolo_annotations(
+ images_directory_path=images_directory_path,
+ annotations_directory_path=annotations_directory_path,
+ data_yaml_path=data_yaml_path,
+ force_masks=force_masks,
+ )
+ returnDetectionDataset(classes=classes,images=images,annotations=annotations)
+
+ defas_yolo(
+ self,
+ images_directory_path:Optional[str]=None,
+ annotations_directory_path:Optional[str]=None,
+ data_yaml_path:Optional[str]=None,
+ min_image_area_percentage:float=0.0,
+ max_image_area_percentage:float=1.0,
+ approximation_percentage:float=0.0,
+ )->None:
+"""
+ Exports the dataset to YOLO format. This method saves the images and their corresponding
+ annotations in YOLO format, which is a simple text file that describes an object in the image. It also allows
+ for the optional saving of a data.yaml file, used in YOLOv5, that contains metadata about the dataset.
+
+ The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
+
+ Args:
+ images_directory_path (Optional[str]): The path to the directory where the images should be saved.
+ If not provided, images will not be saved.
+ annotations_directory_path (Optional[str]): The path to the directory where the annotations in
+ YOLO format should be saved. If not provided, annotations will not be saved.
+ data_yaml_path (Optional[str]): The path where the data.yaml file should be saved.
+ If not provided, the file will not be saved.
+ min_image_area_percentage (float): The minimum percentage of detection area relative to
+ the image area for a detection to be included.
+ max_image_area_percentage (float): The maximum percentage of detection area relative to
+ the image area for a detection to be included.
+ approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,
+ in the range [0, 1). This is useful for simplifying the annotations.
+ """
+ ifimages_directory_pathisnotNone:
+ save_dataset_images(
+ images_directory_path=images_directory_path,images=self.images
+ )
+ ifannotations_directory_pathisnotNone:
+ save_yolo_annotations(
+ annotations_directory_path=annotations_directory_path,
+ images=self.images,
+ annotations=self.annotations,
+ min_image_area_percentage=min_image_area_percentage,
+ max_image_area_percentage=max_image_area_percentage,
+ approximation_percentage=approximation_percentage,
+ )
+ ifdata_yaml_pathisnotNone:
+ save_data_yaml(data_yaml_path=data_yaml_path,classes=self.classes)
+
+ @classmethod
+ deffrom_coco(
+ cls,
+ images_directory_path:str,
+ annotations_path:str,
+ force_masks:bool=False,
+ )->DetectionDataset:
+"""
+ Creates a Dataset instance from YOLO formatted data.
+
+ Args:
+ images_directory_path (str): The path to the directory containing the images.
+ annotations_path (str): The path to the json annotation files.
+ force_masks (bool, optional): If True, forces masks to be loaded for all annotations, regardless of whether they are present.
+
+ Returns:
+ DetectionDataset: A DetectionDataset instance containing the loaded images and annotations.
+
+ Example:
+ ```python
+ >>> import roboflow
+ >>> from roboflow import Roboflow
+ >>> import supervision as sv
+
+ >>> roboflow.login()
+
+ >>> rf = Roboflow()
+
+ >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)
+ >>> dataset = project.version(PROJECT_VERSION).download("coco")
+
+ >>> ds = sv.DetectionDataset.from_coco(
+ ... images_directory_path=f"{dataset.location}/train",
+ ... annotations_path=f"{dataset.location}/train/_annotations.coco.json",
+ ... )
+
+ >>> ds.classes
+ ['dog', 'person']
+ ```
+ """
+ classes,images,annotations=load_coco_annotations(
+ images_directory_path=images_directory_path,
+ annotations_path=annotations_path,
+ force_masks=force_masks,
+ )
+ returnDetectionDataset(classes=classes,images=images,annotations=annotations)
+
+ defas_coco(
+ self,
+ images_directory_path:Optional[str]=None,
+ annotations_path:Optional[str]=None,
+ min_image_area_percentage:float=0.0,
+ max_image_area_percentage:float=1.0,
+ approximation_percentage:float=0.0,
+ licenses:Optional[list]=None,
+ info:Optional[dict]=None,
+ )->None:
+"""
+ Exports the dataset to COCO format. This method saves the images and their corresponding
+ annotations in COCO format, which is a simple json file that describes an object in the image.
+ Annotation json file also include category maps.
+
+ The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
+
+ Args:
+ images_directory_path (Optional[str]): The path to the directory where the images should be saved.
+ If not provided, images will not be saved.
+ annotations_directory_path (Optional[str]): The path to the directory where the annotations in
+ YOLO format should be saved. If not provided, annotations will not be saved.
+ min_image_area_percentage (float): The minimum percentage of detection area relative to
+ the image area for a detection to be included.
+ max_image_area_percentage (float): The maximum percentage of detection area relative to
+ the image area for a detection to be included.
+ approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,
+ in the range [0, 1). This is useful for simplifying the annotations.
+ licenses (Optional[str]): List of licenses for images
+ info (Optional[dict]): Information of Dataset as dictionary
+ """
+ ifimages_directory_pathisnotNone:
+ save_dataset_images(
+ images_directory_path=images_directory_path,images=self.images
+ )
+ ifannotations_pathisnotNone:
+ save_coco_annotations(
+ annotation_path=annotations_path,
+ images=self.images,
+ annotations=self.annotations,
+ classes=self.classes,
+ min_image_area_percentage=min_image_area_percentage,
+ max_image_area_percentage=max_image_area_percentage,
+ approximation_percentage=approximation_percentage,
+ licenses=licenses,
+ info=info,
+ )
+
Iterate over the images and annotations in the dataset.
+
+
Yields:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ str
+
+
+
+
Iterator[Tuple[str, np.ndarray, Detections]]: An iterator that yields tuples containing the image name,
+ the image data, and its corresponding annotation.
+
+
+
+
+
+
+
+ Source code in supervision/dataset/core.py
+
68
+69
+70
+71
+72
+73
+74
+75
+76
+77
def__iter__(self)->Iterator[Tuple[str,np.ndarray,Detections]]:
+"""
+ Iterate over the images and annotations in the dataset.
+
+ Yields:
+ Iterator[Tuple[str, np.ndarray, Detections]]: An iterator that yields tuples containing the image name,
+ the image data, and its corresponding annotation.
+ """
+ forimage_name,imageinself.images.items():
+ yieldimage_name,image,self.annotations.get(image_name,None)
+
Exports the dataset to COCO format. This method saves the images and their corresponding
+annotations in COCO format, which is a simple json file that describes an object in the image.
+Annotation json file also include category maps.
+
The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
+
+
Parameters:
+
+
+
+
Name
+
Type
+
Description
+
Default
+
+
+
+
+
images_directory_path
+
+ Optional[str]
+
+
+
+
The path to the directory where the images should be saved.
+If not provided, images will not be saved.
+
+
+
+ None
+
+
+
+
annotations_directory_path
+
+ Optional[str]
+
+
+
+
The path to the directory where the annotations in
+YOLO format should be saved. If not provided, annotations will not be saved.
+
+
+
+ required
+
+
+
+
min_image_area_percentage
+
+ float
+
+
+
+
The minimum percentage of detection area relative to
+the image area for a detection to be included.
+
+
+
+ 0.0
+
+
+
+
max_image_area_percentage
+
+ float
+
+
+
+
The maximum percentage of detection area relative to
+the image area for a detection to be included.
+
+
+
+ 1.0
+
+
+
+
approximation_percentage
+
+ float
+
+
+
+
The percentage of polygon points to be removed from the input polygon,
+in the range [0, 1). This is useful for simplifying the annotations.
+
+
+
+ 0.0
+
+
+
+
licenses
+
+ Optional[str]
+
+
+
+
List of licenses for images
+
+
+
+ None
+
+
+
+
info
+
+ Optional[dict]
+
+
+
+
Information of Dataset as dictionary
+
+
+
+ None
+
+
+
+
+
+
+ Source code in supervision/dataset/core.py
+
defas_coco(
+ self,
+ images_directory_path:Optional[str]=None,
+ annotations_path:Optional[str]=None,
+ min_image_area_percentage:float=0.0,
+ max_image_area_percentage:float=1.0,
+ approximation_percentage:float=0.0,
+ licenses:Optional[list]=None,
+ info:Optional[dict]=None,
+)->None:
+"""
+ Exports the dataset to COCO format. This method saves the images and their corresponding
+ annotations in COCO format, which is a simple json file that describes an object in the image.
+ Annotation json file also include category maps.
+
+ The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
+
+ Args:
+ images_directory_path (Optional[str]): The path to the directory where the images should be saved.
+ If not provided, images will not be saved.
+ annotations_directory_path (Optional[str]): The path to the directory where the annotations in
+ YOLO format should be saved. If not provided, annotations will not be saved.
+ min_image_area_percentage (float): The minimum percentage of detection area relative to
+ the image area for a detection to be included.
+ max_image_area_percentage (float): The maximum percentage of detection area relative to
+ the image area for a detection to be included.
+ approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,
+ in the range [0, 1). This is useful for simplifying the annotations.
+ licenses (Optional[str]): List of licenses for images
+ info (Optional[dict]): Information of Dataset as dictionary
+ """
+ ifimages_directory_pathisnotNone:
+ save_dataset_images(
+ images_directory_path=images_directory_path,images=self.images
+ )
+ ifannotations_pathisnotNone:
+ save_coco_annotations(
+ annotation_path=annotations_path,
+ images=self.images,
+ annotations=self.annotations,
+ classes=self.classes,
+ min_image_area_percentage=min_image_area_percentage,
+ max_image_area_percentage=max_image_area_percentage,
+ approximation_percentage=approximation_percentage,
+ licenses=licenses,
+ info=info,
+ )
+
Exports the dataset to PASCAL VOC format. This method saves the images and their corresponding annotations in
+PASCAL VOC format, which consists of XML files. The method allows filtering the detections based on their area
+percentage.
+
+
Parameters:
+
+
+
+
Name
+
Type
+
Description
+
Default
+
+
+
+
+
images_directory_path
+
+ Optional[str]
+
+
+
+
The path to the directory where the images should be saved.
+If not provided, images will not be saved.
+
+
+
+ None
+
+
+
+
annotations_directory_path
+
+ Optional[str]
+
+
+
+
The path to the directory where the annotations in
+PASCAL VOC format should be saved. If not provided, annotations will not be saved.
+
+
+
+ None
+
+
+
+
min_image_area_percentage
+
+ float
+
+
+
+
The minimum percentage of detection area relative to
+the image area for a detection to be included.
+
+
+
+ 0.0
+
+
+
+
max_image_area_percentage
+
+ float
+
+
+
+
The maximum percentage of detection area relative to
+the image area for a detection to be included.
+
+
+
+ 1.0
+
+
+
+
approximation_percentage
+
+ float
+
+
+
+
The percentage of polygon points to be removed from the input polygon, in the range [0, 1).
+
+
+
+ 0.0
+
+
+
+
+
+
+ Source code in supervision/dataset/core.py
+
defas_pascal_voc(
+ self,
+ images_directory_path:Optional[str]=None,
+ annotations_directory_path:Optional[str]=None,
+ min_image_area_percentage:float=0.0,
+ max_image_area_percentage:float=1.0,
+ approximation_percentage:float=0.0,
+)->None:
+"""
+ Exports the dataset to PASCAL VOC format. This method saves the images and their corresponding annotations in
+ PASCAL VOC format, which consists of XML files. The method allows filtering the detections based on their area
+ percentage.
+
+ Args:
+ images_directory_path (Optional[str]): The path to the directory where the images should be saved.
+ If not provided, images will not be saved.
+ annotations_directory_path (Optional[str]): The path to the directory where the annotations in
+ PASCAL VOC format should be saved. If not provided, annotations will not be saved.
+ min_image_area_percentage (float): The minimum percentage of detection area relative to
+ the image area for a detection to be included.
+ max_image_area_percentage (float): The maximum percentage of detection area relative to
+ the image area for a detection to be included.
+ approximation_percentage (float): The percentage of polygon points to be removed from the input polygon, in the range [0, 1).
+ """
+ ifimages_directory_path:
+ images_path=Path(images_directory_path)
+ images_path.mkdir(parents=True,exist_ok=True)
+
+ ifannotations_directory_path:
+ annotations_path=Path(annotations_directory_path)
+ annotations_path.mkdir(parents=True,exist_ok=True)
+
+ forimage_name,imageinself.images.items():
+ detections=self.annotations[image_name]
+
+ ifimages_directory_path:
+ cv2.imwrite(str(images_path/image_name),image)
+
+ ifannotations_directory_path:
+ annotation_name=Path(image_name).stem
+ pascal_voc_xml=detections_to_pascal_voc(
+ detections=detections,
+ classes=self.classes,
+ filename=image_name,
+ image_shape=image.shape,
+ min_image_area_percentage=min_image_area_percentage,
+ max_image_area_percentage=max_image_area_percentage,
+ approximation_percentage=approximation_percentage,
+ )
+
+ withopen(annotations_path/f"{annotation_name}.xml","w")asf:
+ f.write(pascal_voc_xml)
+
Exports the dataset to YOLO format. This method saves the images and their corresponding
+annotations in YOLO format, which is a simple text file that describes an object in the image. It also allows
+for the optional saving of a data.yaml file, used in YOLOv5, that contains metadata about the dataset.
+
The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
+
+
Parameters:
+
+
+
+
Name
+
Type
+
Description
+
Default
+
+
+
+
+
images_directory_path
+
+ Optional[str]
+
+
+
+
The path to the directory where the images should be saved.
+If not provided, images will not be saved.
+
+
+
+ None
+
+
+
+
annotations_directory_path
+
+ Optional[str]
+
+
+
+
The path to the directory where the annotations in
+YOLO format should be saved. If not provided, annotations will not be saved.
+
+
+
+ None
+
+
+
+
data_yaml_path
+
+ Optional[str]
+
+
+
+
The path where the data.yaml file should be saved.
+If not provided, the file will not be saved.
+
+
+
+ None
+
+
+
+
min_image_area_percentage
+
+ float
+
+
+
+
The minimum percentage of detection area relative to
+the image area for a detection to be included.
+
+
+
+ 0.0
+
+
+
+
max_image_area_percentage
+
+ float
+
+
+
+
The maximum percentage of detection area relative to
+the image area for a detection to be included.
+
+
+
+ 1.0
+
+
+
+
approximation_percentage
+
+ float
+
+
+
+
The percentage of polygon points to be removed from the input polygon,
+in the range [0, 1). This is useful for simplifying the annotations.
+
+
+
+ 0.0
+
+
+
+
+
+
+ Source code in supervision/dataset/core.py
+
defas_yolo(
+ self,
+ images_directory_path:Optional[str]=None,
+ annotations_directory_path:Optional[str]=None,
+ data_yaml_path:Optional[str]=None,
+ min_image_area_percentage:float=0.0,
+ max_image_area_percentage:float=1.0,
+ approximation_percentage:float=0.0,
+)->None:
+"""
+ Exports the dataset to YOLO format. This method saves the images and their corresponding
+ annotations in YOLO format, which is a simple text file that describes an object in the image. It also allows
+ for the optional saving of a data.yaml file, used in YOLOv5, that contains metadata about the dataset.
+
+ The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
+
+ Args:
+ images_directory_path (Optional[str]): The path to the directory where the images should be saved.
+ If not provided, images will not be saved.
+ annotations_directory_path (Optional[str]): The path to the directory where the annotations in
+ YOLO format should be saved. If not provided, annotations will not be saved.
+ data_yaml_path (Optional[str]): The path where the data.yaml file should be saved.
+ If not provided, the file will not be saved.
+ min_image_area_percentage (float): The minimum percentage of detection area relative to
+ the image area for a detection to be included.
+ max_image_area_percentage (float): The maximum percentage of detection area relative to
+ the image area for a detection to be included.
+ approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,
+ in the range [0, 1). This is useful for simplifying the annotations.
+ """
+ ifimages_directory_pathisnotNone:
+ save_dataset_images(
+ images_directory_path=images_directory_path,images=self.images
+ )
+ ifannotations_directory_pathisnotNone:
+ save_yolo_annotations(
+ annotations_directory_path=annotations_directory_path,
+ images=self.images,
+ annotations=self.annotations,
+ min_image_area_percentage=min_image_area_percentage,
+ max_image_area_percentage=max_image_area_percentage,
+ approximation_percentage=approximation_percentage,
+ )
+ ifdata_yaml_pathisnotNone:
+ save_data_yaml(data_yaml_path=data_yaml_path,classes=self.classes)
+
defsplit(
+ self,split_ratio=0.8,random_state=None,shuffle:bool=True
+)->Tuple[DetectionDataset,DetectionDataset]:
+"""
+ Splits the dataset into two parts (training and testing) using the provided split_ratio.
+
+ Args:
+ split_ratio (float, optional): The ratio of the training set to the entire dataset.
+ random_state (int, optional): The seed for the random number generator. This is used for reproducibility.
+ shuffle (bool, optional): Whether to shuffle the data before splitting.
+
+ Returns:
+ Tuple[DetectionDataset, DetectionDataset]: A tuple containing the training and testing datasets.
+
+ Example:
+ ```python
+ >>> import supervision as sv
+
+ >>> ds = sv.DetectionDataset(...)
+ >>> train_ds, test_ds = ds.split(split_ratio=0.7, random_state=42, shuffle=True)
+ >>> len(train_ds), len(test_ds)
+ (700, 300)
+ ```
+ """
+
+ image_names=list(self.images.keys())
+ train_names,test_names=train_test_split(
+ data=image_names,
+ train_ratio=split_ratio,
+ random_state=random_state,
+ shuffle=shuffle,
+ )
+
+ train_dataset=DetectionDataset(
+ classes=self.classes,
+ images={name:self.images[name]fornameintrain_names},
+ annotations={name:self.annotations[name]fornameintrain_names},
+ )
+ test_dataset=DetectionDataset(
+ classes=self.classes,
+ images={name:self.images[name]fornameintest_names},
+ annotations={name:self.annotations[name]fornameintest_names},
+ )
+ returntrain_dataset,test_dataset
+
defsplit(
+ self,split_ratio=0.8,random_state=None,shuffle:bool=True
+)->Tuple[ClassificationDataset,ClassificationDataset]:
+"""
+ Splits the dataset into two parts (training and testing) using the provided split_ratio.
+
+ Args:
+ split_ratio (float, optional): The ratio of the training set to the entire dataset.
+ random_state (int, optional): The seed for the random number generator. This is used for reproducibility.
+ shuffle (bool, optional): Whether to shuffle the data before splitting.
+
+ Returns:
+ Tuple[ClassificationDataset, ClassificationDataset]: A tuple containing the training and testing datasets.
+
+ Example:
+ ```python
+ >>> import supervision as sv
+
+ >>> cd = sv.ClassificationDataset(...)
+ >>> train_cd, test_cd = cd.split(split_ratio=0.7, random_state=42, shuffle=True)
+ >>> len(train_cd), len(test_cd)
+ (700, 300)
+ ```
+ """
+ image_names=list(self.images.keys())
+ train_names,test_names=train_test_split(
+ data=image_names,
+ train_ratio=split_ratio,
+ random_state=random_state,
+ shuffle=shuffle,
+ )
+
+ train_dataset=ClassificationDataset(
+ classes=self.classes,
+ images={name:self.images[name]fornameintrain_names},
+ annotations={name:self.annotations[name]fornameintrain_names},
+ )
+ test_dataset=ClassificationDataset(
+ classes=self.classes,
+ images={name:self.images[name]fornameintest_names},
+ annotations={name:self.annotations[name]fornameintest_names},
+ )
+ returntrain_dataset,test_dataset
+
classBoxAnnotator:
+"""
+ A class for drawing bounding boxes on an image using detections provided.
+
+ Attributes:
+ color (Union[Color, ColorPalette]): The color to draw the bounding box, can be a single color or a color palette
+ thickness (int): The thickness of the bounding box lines, default is 2
+ text_color (Color): The color of the text on the bounding box, default is white
+ text_scale (float): The scale of the text on the bounding box, default is 0.5
+ text_thickness (int): The thickness of the text on the bounding box, default is 1
+ text_padding (int): The padding around the text on the bounding box, default is 5
+
+ """
+
+ def__init__(
+ self,
+ color:Union[Color,ColorPalette]=ColorPalette.default(),
+ thickness:int=2,
+ text_color:Color=Color.black(),
+ text_scale:float=0.5,
+ text_thickness:int=1,
+ text_padding:int=10,
+ ):
+ self.color:Union[Color,ColorPalette]=color
+ self.thickness:int=thickness
+ self.text_color:Color=text_color
+ self.text_scale:float=text_scale
+ self.text_thickness:int=text_thickness
+ self.text_padding:int=text_padding
+
+ defannotate(
+ self,
+ scene:np.ndarray,
+ detections:Detections,
+ labels:Optional[List[str]]=None,
+ skip_label:bool=False,
+ )->np.ndarray:
+"""
+ Draws bounding boxes on the frame using the detections provided.
+
+ Args:
+ scene (np.ndarray): The image on which the bounding boxes will be drawn
+ detections (Detections): The detections for which the bounding boxes will be drawn
+ labels (Optional[List[str]]): An optional list of labels corresponding to each detection. If `labels` are not provided, corresponding `class_id` will be used as label.
+ skip_label (bool): Is set to `True`, skips bounding box label annotation.
+ Returns:
+ np.ndarray: The image with the bounding boxes drawn on it
+
+ Example:
+ ```python
+ >>> import supervision as sv
+
+ >>> classes = ['person', ...]
+ >>> image = ...
+ >>> detections = sv.Detections(...)
+
+ >>> box_annotator = sv.BoxAnnotator()
+ >>> labels = [
+ ... f"{classes[class_id]} {confidence:0.2f}"
+ ... for _, _, confidence, class_id, _
+ ... in detections
+ ... ]
+ >>> annotated_frame = box_annotator.annotate(
+ ... scene=image.copy(),
+ ... detections=detections,
+ ... labels=labels
+ ... )
+ ```
+ """
+ font=cv2.FONT_HERSHEY_SIMPLEX
+ foriinrange(len(detections)):
+ x1,y1,x2,y2=detections.xyxy[i].astype(int)
+ class_id=(
+ detections.class_id[i]ifdetections.class_idisnotNoneelseNone
+ )
+ idx=class_idifclass_idisnotNoneelsei
+ color=(
+ self.color.by_idx(idx)
+ ifisinstance(self.color,ColorPalette)
+ elseself.color
+ )
+ cv2.rectangle(
+ img=scene,
+ pt1=(x1,y1),
+ pt2=(x2,y2),
+ color=color.as_bgr(),
+ thickness=self.thickness,
+ )
+ ifskip_label:
+ continue
+
+ text=(
+ f"{class_id}"
+ if(labelsisNoneorlen(detections)!=len(labels))
+ elselabels[i]
+ )
+
+ text_width,text_height=cv2.getTextSize(
+ text=text,
+ fontFace=font,
+ fontScale=self.text_scale,
+ thickness=self.text_thickness,
+ )[0]
+
+ text_x=x1+self.text_padding
+ text_y=y1-self.text_padding
+
+ text_background_x1=x1
+ text_background_y1=y1-2*self.text_padding-text_height
+
+ text_background_x2=x1+2*self.text_padding+text_width
+ text_background_y2=y1
+
+ cv2.rectangle(
+ img=scene,
+ pt1=(text_background_x1,text_background_y1),
+ pt2=(text_background_x2,text_background_y2),
+ color=color.as_bgr(),
+ thickness=cv2.FILLED,
+ )
+ cv2.putText(
+ img=scene,
+ text=text,
+ org=(text_x,text_y),
+ fontFace=font,
+ fontScale=self.text_scale,
+ color=self.text_color.as_rgb(),
+ thickness=self.text_thickness,
+ lineType=cv2.LINE_AA,
+ )
+ returnscene
+
classMaskAnnotator:
+"""
+ A class for overlaying masks on an image using detections provided.
+
+ Attributes:
+ color (Union[Color, ColorPalette]): The color to fill the mask, can be a single color or a color palette
+ """
+
+ def__init__(
+ self,
+ color:Union[Color,ColorPalette]=ColorPalette.default(),
+ ):
+ self.color:Union[Color,ColorPalette]=color
+
+ defannotate(
+ self,scene:np.ndarray,detections:Detections,opacity:float=0.5
+ )->np.ndarray:
+"""
+ Overlays the masks on the given image based on the provided detections, with a specified opacity.
+
+ Args:
+ scene (np.ndarray): The image on which the masks will be overlaid
+ detections (Detections): The detections for which the masks will be overlaid
+ opacity (float): The opacity of the masks, between 0 and 1, default is 0.5
+
+ Returns:
+ np.ndarray: The image with the masks overlaid
+ """
+ ifdetections.maskisNone:
+ returnscene
+
+ foriinnp.flip(np.argsort(detections.area)):
+ class_id=(
+ detections.class_id[i]ifdetections.class_idisnotNoneelseNone
+ )
+ idx=class_idifclass_idisnotNoneelsei
+ color=(
+ self.color.by_idx(idx)
+ ifisinstance(self.color,ColorPalette)
+ elseself.color
+ )
+
+ mask=detections.mask[i]
+ colored_mask=np.zeros_like(scene,dtype=np.uint8)
+ colored_mask[:]=color.as_bgr()
+
+ scene=np.where(
+ np.expand_dims(mask,axis=-1),
+ np.uint8(opacity*colored_mask+(1-opacity)*scene),
+ scene,
+ )
+
+ returnscene
+
defannotate(
+ self,scene:np.ndarray,detections:Detections,opacity:float=0.5
+)->np.ndarray:
+"""
+ Overlays the masks on the given image based on the provided detections, with a specified opacity.
+
+ Args:
+ scene (np.ndarray): The image on which the masks will be overlaid
+ detections (Detections): The detections for which the masks will be overlaid
+ opacity (float): The opacity of the masks, between 0 and 1, default is 0.5
+
+ Returns:
+ np.ndarray: The image with the masks overlaid
+ """
+ ifdetections.maskisNone:
+ returnscene
+
+ foriinnp.flip(np.argsort(detections.area)):
+ class_id=(
+ detections.class_id[i]ifdetections.class_idisnotNoneelseNone
+ )
+ idx=class_idifclass_idisnotNoneelsei
+ color=(
+ self.color.by_idx(idx)
+ ifisinstance(self.color,ColorPalette)
+ elseself.color
+ )
+
+ mask=detections.mask[i]
+ colored_mask=np.zeros_like(scene,dtype=np.uint8)
+ colored_mask[:]=color.as_bgr()
+
+ scene=np.where(
+ np.expand_dims(mask,axis=-1),
+ np.uint8(opacity*colored_mask+(1-opacity)*scene),
+ scene,
+ )
+
+ returnscene
+
Calculate the area of each detection in the set of object detections. If masks field is defined property
+returns are of each mask. If only box is given property return area of each box.
+
+
Returns:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ np.ndarray
+
+
+
+
np.ndarray: An array of floats containing the area of each detection in the format of (area_1, area_2, ..., area_n), where n is the number of detections.
Calculate the area of each bounding box in the set of object detections.
+
+
Returns:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ np.ndarray
+
+
+
+
np.ndarray: An array of floats containing the area of each bounding box in the format of (area_1, area_2, ..., area_n), where n is the number of detections.
defget_anchor_coordinates(self,anchor:Position)->np.ndarray:
+"""
+ Returns the bounding box coordinates for a specific anchor.
+
+ Args:
+ anchor (Position): Position of bounding box anchor for which to return the coordinates.
+
+ Returns:
+ np.ndarray: An array of shape `(n, 2)` containing the bounding box anchor coordinates in format `[x, y]`.
+ """
+ ifanchor==Position.CENTER:
+ returnnp.array(
+ [
+ (self.xyxy[:,0]+self.xyxy[:,2])/2,
+ (self.xyxy[:,1]+self.xyxy[:,3])/2,
+ ]
+ ).transpose()
+ elifanchor==Position.BOTTOM_CENTER:
+ returnnp.array(
+ [(self.xyxy[:,0]+self.xyxy[:,2])/2,self.xyxy[:,3]]
+ ).transpose()
+
+ raiseValueError(f"{anchor} is not supported.")
+
Merge a list of Detections objects into a single Detections object.
+
This method takes a list of Detections objects and combines their respective fields (xyxy, mask,
+confidence, class_id, and tracker_id) into a single Detections object. If all elements in a field are not
+None, the corresponding field will be stacked. Otherwise, the field will be set to None.
@classmethod
+defmerge(cls,detections_list:List[Detections])->Detections:
+"""
+ Merge a list of Detections objects into a single Detections object.
+
+ This method takes a list of Detections objects and combines their respective fields (`xyxy`, `mask`,
+ `confidence`, `class_id`, and `tracker_id`) into a single Detections object. If all elements in a field are not
+ `None`, the corresponding field will be stacked. Otherwise, the field will be set to `None`.
+
+ Args:
+ detections_list (List[Detections]): A list of Detections objects to merge.
+
+ Returns:
+ (Detections): A single Detections object containing the merged data from the input list.
+
+ Example:
+ ```python
+ >>> from supervision import Detections
+
+ >>> detections_1 = Detections(...)
+ >>> detections_2 = Detections(...)
+
+ >>> merged_detections = Detections.merge([detections_1, detections_2])
+ ```
+ """
+ iflen(detections_list)==0:
+ returnDetections.empty()
+
+ detections_tuples_list=[astuple(detection)fordetectionindetections_list]
+ xyxy,mask,confidence,class_id,tracker_id=[
+ list(field)forfieldinzip(*detections_tuples_list)
+ ]
+
+ all_not_none=lambdal:all(xisnotNoneforxinl)
+
+ xyxy=np.vstack(xyxy)
+ mask=np.vstack(mask)ifall_not_none(mask)elseNone
+ confidence=np.hstack(confidence)ifall_not_none(confidence)elseNone
+ class_id=np.hstack(class_id)ifall_not_none(class_id)elseNone
+ tracker_id=np.hstack(tracker_id)ifall_not_none(tracker_id)elseNone
+
+ returncls(
+ xyxy=xyxy,
+ mask=mask,
+ confidence=confidence,
+ class_id=class_id,
+ tracker_id=tracker_id,
+ )
+
defwith_nms(
+ self,threshold:float=0.5,class_agnostic:bool=False
+)->Detections:
+"""
+ Perform non-maximum suppression on the current set of object detections.
+
+ Args:
+ threshold (float, optional): The intersection-over-union threshold to use for non-maximum suppression. Defaults to 0.5.
+ class_agnostic (bool, optional): Whether to perform class-agnostic non-maximum suppression. If True, the class_id of each detection will be ignored. Defaults to False.
+
+ Returns:
+ Detections: A new Detections object containing the subset of detections after non-maximum suppression.
+
+ Raises:
+ AssertionError: If `confidence` is None and class_agnostic is False. If `class_id` is None and class_agnostic is False.
+ """
+ iflen(self)==0:
+ returnself
+
+ assert(
+ self.confidenceisnotNone
+ ),f"Detections confidence must be given for NMS to be executed."
+
+ ifclass_agnostic:
+ predictions=np.hstack((self.xyxy,self.confidence.reshape(-1,1)))
+ indices=non_max_suppression(
+ predictions=predictions,iou_threshold=threshold
+ )
+ returnself[indices]
+
+ assertself.class_idisnotNone,(
+ f"Detections class_id must be given for NMS to be executed. If you intended to perform class agnostic "
+ f"NMS set class_agnostic=True."
+ )
+
+ predictions=np.hstack(
+ (self.xyxy,self.confidence.reshape(-1,1),self.class_id.reshape(-1,1))
+ )
+ indices=non_max_suppression(predictions=predictions,iou_threshold=threshold)
+ returnself[indices]
+
classPolygonZone:
+"""
+ A class for defining a polygon-shaped zone within a frame for detecting objects.
+
+ Attributes:
+ polygon (np.ndarray): A polygon represented by a numpy array of shape `(N, 2)`, containing the `x`, `y` coordinates of the points.
+ frame_resolution_wh (Tuple[int, int]): The frame resolution (width, height)
+ triggering_position (Position): The position within the bounding box that triggers the zone (default: Position.BOTTOM_CENTER)
+ current_count (int): The current count of detected objects within the zone
+ mask (np.ndarray): The 2D bool mask for the polygon zone
+ """
+
+ def__init__(
+ self,
+ polygon:np.ndarray,
+ frame_resolution_wh:Tuple[int,int],
+ triggering_position:Position=Position.BOTTOM_CENTER,
+ ):
+ self.polygon=polygon.astype(int)
+ self.frame_resolution_wh=frame_resolution_wh
+ self.triggering_position=triggering_position
+ self.current_count=0
+
+ width,height=frame_resolution_wh
+ self.mask=polygon_to_mask(
+ polygon=polygon,resolution_wh=(width+1,height+1)
+ )
+
+ deftrigger(self,detections:Detections)->np.ndarray:
+"""
+ Determines if the detections are within the polygon zone.
+
+ Parameters:
+ detections (Detections): The detections to be checked against the polygon zone
+
+ Returns:
+ np.ndarray: A boolean numpy array indicating if each detection is within the polygon zone
+ """
+
+ clipped_xyxy=clip_boxes(
+ boxes_xyxy=detections.xyxy,frame_resolution_wh=self.frame_resolution_wh
+ )
+ clipped_detections=replace(detections,xyxy=clipped_xyxy)
+ clipped_anchors=np.ceil(
+ clipped_detections.get_anchor_coordinates(anchor=self.triggering_position)
+ ).astype(int)
+ is_in_zone=self.mask[clipped_anchors[:,1],clipped_anchors[:,0]]
+ self.current_count=np.sum(is_in_zone)
+ returnis_in_zone.astype(bool)
+
deftrigger(self,detections:Detections)->np.ndarray:
+"""
+ Determines if the detections are within the polygon zone.
+
+ Parameters:
+ detections (Detections): The detections to be checked against the polygon zone
+
+ Returns:
+ np.ndarray: A boolean numpy array indicating if each detection is within the polygon zone
+ """
+
+ clipped_xyxy=clip_boxes(
+ boxes_xyxy=detections.xyxy,frame_resolution_wh=self.frame_resolution_wh
+ )
+ clipped_detections=replace(detections,xyxy=clipped_xyxy)
+ clipped_anchors=np.ceil(
+ clipped_detections.get_anchor_coordinates(anchor=self.triggering_position)
+ ).astype(int)
+ is_in_zone=self.mask[clipped_anchors[:,1],clipped_anchors[:,0]]
+ self.current_count=np.sum(is_in_zone)
+ returnis_in_zone.astype(bool)
+
classPolygonZoneAnnotator:
+"""
+ A class for annotating a polygon-shaped zone within a frame with a count of detected objects.
+
+ Attributes:
+ zone (PolygonZone): The polygon zone to be annotated
+ color (Color): The color to draw the polygon lines
+ thickness (int): The thickness of the polygon lines, default is 2
+ text_color (Color): The color of the text on the polygon, default is black
+ text_scale (float): The scale of the text on the polygon, default is 0.5
+ text_thickness (int): The thickness of the text on the polygon, default is 1
+ text_padding (int): The padding around the text on the polygon, default is 10
+ font (int): The font type for the text on the polygon, default is cv2.FONT_HERSHEY_SIMPLEX
+ center (Tuple[int, int]): The center of the polygon for text placement
+ """
+
+ def__init__(
+ self,
+ zone:PolygonZone,
+ color:Color,
+ thickness:int=2,
+ text_color:Color=Color.black(),
+ text_scale:float=0.5,
+ text_thickness:int=1,
+ text_padding:int=10,
+ ):
+ self.zone=zone
+ self.color=color
+ self.thickness=thickness
+ self.text_color=text_color
+ self.text_scale=text_scale
+ self.text_thickness=text_thickness
+ self.text_padding=text_padding
+ self.font=cv2.FONT_HERSHEY_SIMPLEX
+ self.center=get_polygon_center(polygon=zone.polygon)
+
+ defannotate(self,scene:np.ndarray,label:Optional[str]=None)->np.ndarray:
+"""
+ Annotates the polygon zone within a frame with a count of detected objects.
+
+ Parameters:
+ scene (np.ndarray): The image on which the polygon zone will be annotated
+ label (Optional[str]): An optional label for the count of detected objects within the polygon zone (default: None)
+
+ Returns:
+ np.ndarray: The image with the polygon zone and count of detected objects
+ """
+ annotated_frame=draw_polygon(
+ scene=scene,
+ polygon=self.zone.polygon,
+ color=self.color,
+ thickness=self.thickness,
+ )
+
+ annotated_frame=draw_text(
+ scene=annotated_frame,
+ text=str(self.zone.current_count)iflabelisNoneelselabel,
+ text_anchor=self.center,
+ background_color=self.color,
+ text_color=self.text_color,
+ text_scale=self.text_scale,
+ text_thickness=self.text_thickness,
+ text_padding=self.text_padding,
+ text_font=self.font,
+ )
+
+ returnannotated_frame
+
defannotate(self,scene:np.ndarray,label:Optional[str]=None)->np.ndarray:
+"""
+ Annotates the polygon zone within a frame with a count of detected objects.
+
+ Parameters:
+ scene (np.ndarray): The image on which the polygon zone will be annotated
+ label (Optional[str]): An optional label for the count of detected objects within the polygon zone (default: None)
+
+ Returns:
+ np.ndarray: The image with the polygon zone and count of detected objects
+ """
+ annotated_frame=draw_polygon(
+ scene=scene,
+ polygon=self.zone.polygon,
+ color=self.color,
+ thickness=self.thickness,
+ )
+
+ annotated_frame=draw_text(
+ scene=annotated_frame,
+ text=str(self.zone.current_count)iflabelisNoneelselabel,
+ text_anchor=self.center,
+ background_color=self.color,
+ text_color=self.text_color,
+ text_scale=self.text_scale,
+ text_thickness=self.text_thickness,
+ text_padding=self.text_padding,
+ text_font=self.font,
+ )
+
+ returnannotated_frame
+
Compute Intersection over Union (IoU) of two sets of bounding boxes - boxes_true and boxes_detection. Both sets
+of boxes are expected to be in (x_min, y_min, x_max, y_max) format.
+
+
Parameters:
+
+
+
+
Name
+
Type
+
Description
+
Default
+
+
+
+
+
boxes_true
+
+ np.ndarray
+
+
+
+
2D np.ndarray representing ground-truth boxes. shape = (N, 4) where N is number of true objects.
+
+
+
+ required
+
+
+
+
boxes_detection
+
+ np.ndarray
+
+
+
+
2D np.ndarray representing detection boxes. shape = (M, 4) where M is number of detected objects.
+
+
+
+ required
+
+
+
+
+
+
Returns:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ np.ndarray
+
+
+
+
np.ndarray: Pairwise IoU of boxes from boxes_true and boxes_detection. shape = (N, M) where N is number of true objects and M is number of detected objects.
+
+
+
+
+
+
+
+ Source code in supervision/detection/utils.py
+
defbox_iou_batch(boxes_true:np.ndarray,boxes_detection:np.ndarray)->np.ndarray:
+"""
+ Compute Intersection over Union (IoU) of two sets of bounding boxes - `boxes_true` and `boxes_detection`. Both sets
+ of boxes are expected to be in `(x_min, y_min, x_max, y_max)` format.
+
+ Args:
+ boxes_true (np.ndarray): 2D `np.ndarray` representing ground-truth boxes. `shape = (N, 4)` where `N` is number of true objects.
+ boxes_detection (np.ndarray): 2D `np.ndarray` representing detection boxes. `shape = (M, 4)` where `M` is number of detected objects.
+
+ Returns:
+ np.ndarray: Pairwise IoU of boxes from `boxes_true` and `boxes_detection`. `shape = (N, M)` where `N` is number of true objects and `M` is number of detected objects.
+ """
+
+ defbox_area(box):
+ return(box[2]-box[0])*(box[3]-box[1])
+
+ area_true=box_area(boxes_true.T)
+ area_detection=box_area(boxes_detection.T)
+
+ top_left=np.maximum(boxes_true[:,None,:2],boxes_detection[:,:2])
+ bottom_right=np.minimum(boxes_true[:,None,2:],boxes_detection[:,2:])
+
+ area_inter=np.prod(np.clip(bottom_right-top_left,a_min=0,a_max=None),2)
+ returnarea_inter/(area_true[:,None]+area_detection-area_inter)
+
defnon_max_suppression(
+ predictions:np.ndarray,iou_threshold:float=0.5
+)->np.ndarray:
+"""
+ Perform Non-Maximum Suppression (NMS) on object detection predictions.
+
+ Args:
+ predictions (np.ndarray): An array of object detection predictions in the format of `(x_min, y_min, x_max, y_max, score)` or `(x_min, y_min, x_max, y_max, score, class)`.
+ iou_threshold (float, optional): The intersection-over-union threshold to use for non-maximum suppression.
+
+ Returns:
+ np.ndarray: A boolean array indicating which predictions to keep after non-maximum suppression.
+
+ Raises:
+ AssertionError: If `iou_threshold` is not within the closed range from `0` to `1`.
+ """
+ assert0<=iou_threshold<=1,(
+ f"Value of `iou_threshold` must be in the closed range from 0 to 1, "
+ f"{iou_threshold} given."
+ )
+ rows,columns=predictions.shape
+
+ # add column #5 - category filled with zeros for agnostic nms
+ ifcolumns==5:
+ predictions=np.c_[predictions,np.zeros(rows)]
+
+ # sort predictions column #4 - score
+ sort_index=np.flip(predictions[:,4].argsort())
+ predictions=predictions[sort_index]
+
+ boxes=predictions[:,:4]
+ categories=predictions[:,5]
+ ious=box_iou_batch(boxes,boxes)
+ ious=ious-np.eye(rows)
+
+ keep=np.ones(rows,dtype=bool)
+
+ forindex,(iou,category)inenumerate(zip(ious,categories)):
+ ifnotkeep[index]:
+ continue
+
+ # drop detections with iou > iou_threshold and same category as current detections
+ condition=(iou>iou_threshold)&(categories==category)
+ keep=keep&~condition
+
+ returnkeep[sort_index.argsort()]
+
defpolygon_to_mask(polygon:np.ndarray,resolution_wh:Tuple[int,int])->np.ndarray:
+"""Generate a mask from a polygon.
+
+ Args:
+ polygon (np.ndarray): The polygon for which the mask should be generated, given as a list of vertices.
+ resolution_wh (Tuple[int, int]): The width and height of the desired resolution.
+
+ Returns:
+ np.ndarray: The generated 2D mask, where the polygon is marked with `1`'s and the rest is filled with `0`'s.
+ """
+ width,height=resolution_wh
+ mask=np.zeros((height,width),dtype=np.uint8)
+ cv2.fillPoly(mask,[polygon],color=1)
+ returnmask
+
A binary mask represented as a 2D NumPy array of shape (H, W),
+where H and W are the height and width of the mask, respectively.
+
+
+
+ required
+
+
+
+
+
+
Returns:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ List[np.ndarray]
+
+
+
+
List[np.ndarray]: A list of polygons, where each polygon is represented by a NumPy array of shape (N, 2),
+containing the x, y coordinates of the points. Polygons with fewer points than MIN_POLYGON_POINT_COUNT = 3
+are excluded from the output.
+
+
+
+
+
+
+
+ Source code in supervision/detection/utils.py
+
defmask_to_polygons(mask:np.ndarray)->List[np.ndarray]:
+"""
+ Converts a binary mask to a list of polygons.
+
+ Parameters:
+ mask (np.ndarray): A binary mask represented as a 2D NumPy array of shape `(H, W)`,
+ where H and W are the height and width of the mask, respectively.
+
+ Returns:
+ List[np.ndarray]: A list of polygons, where each polygon is represented by a NumPy array of shape `(N, 2)`,
+ containing the `x`, `y` coordinates of the points. Polygons with fewer points than `MIN_POLYGON_POINT_COUNT = 3`
+ are excluded from the output.
+ """
+
+ contours,_=cv2.findContours(
+ mask.astype(np.uint8),cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE
+ )
+ return[
+ np.squeeze(contour,axis=1)
+ forcontourincontours
+ ifcontour.shape[0]>=MIN_POLYGON_POINT_COUNT
+ ]
+
defpolygon_to_xyxy(polygon:np.ndarray)->np.ndarray:
+"""
+ Converts a polygon represented by a NumPy array into a bounding box.
+
+ Parameters:
+ polygon (np.ndarray): A polygon represented by a NumPy array of shape `(N, 2)`,
+ containing the `x`, `y` coordinates of the points.
+
+ Returns:
+ np.ndarray: A 1D NumPy array containing the bounding box `(x_min, y_min, x_max, y_max)` of the input polygon.
+ """
+ x_min,y_min=np.min(polygon,axis=0)
+ x_max,y_max=np.max(polygon,axis=0)
+ returnnp.array([x_min,y_min,x_max,y_max])
+
A list of polygons, where each polygon is represented by a NumPy array of shape (N, 2),
+containing the x, y coordinates of the points.
+
+
+
+ required
+
+
+
+
min_area
+
+ Optional[float]
+
+
+
+
The minimum area threshold. Only polygons with an area greater than or equal to this value
+will be included in the output. If set to None, no minimum area constraint will be applied.
+
+
+
+ None
+
+
+
+
max_area
+
+ Optional[float]
+
+
+
+
The maximum area threshold. Only polygons with an area less than or equal to this value
+will be included in the output. If set to None, no maximum area constraint will be applied.
+
+
+
+ None
+
+
+
+
+
+
Returns:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ List[np.ndarray]
+
+
+
+
List[np.ndarray]: A new list of polygons containing only those with areas within the specified thresholds.
+
+
+
+
+
+
+
+ Source code in supervision/detection/utils.py
+
deffilter_polygons_by_area(
+ polygons:List[np.ndarray],
+ min_area:Optional[float]=None,
+ max_area:Optional[float]=None,
+)->List[np.ndarray]:
+"""
+ Filters a list of polygons based on their area.
+
+ Parameters:
+ polygons (List[np.ndarray]): A list of polygons, where each polygon is represented by a NumPy array of shape `(N, 2)`,
+ containing the `x`, `y` coordinates of the points.
+ min_area (Optional[float]): The minimum area threshold. Only polygons with an area greater than or equal to this value
+ will be included in the output. If set to None, no minimum area constraint will be applied.
+ max_area (Optional[float]): The maximum area threshold. Only polygons with an area less than or equal to this value
+ will be included in the output. If set to None, no maximum area constraint will be applied.
+
+ Returns:
+ List[np.ndarray]: A new list of polygons containing only those with areas within the specified thresholds.
+ """
+ ifmin_areaisNoneandmax_areaisNone:
+ returnpolygons
+ ares=[cv2.contourArea(polygon)forpolygoninpolygons]
+ return[
+ polygon
+ forpolygon,areainzip(polygons,ares)
+ if(min_areaisNoneorarea>=min_area)
+ and(max_areaisNoneorarea<=max_area)
+ ]
+
defdraw_line(
+ scene:np.ndarray,start:Point,end:Point,color:Color,thickness:int=2
+)->np.ndarray:
+"""
+ Draws a line on a given scene.
+
+ Parameters:
+ scene (np.ndarray): The scene on which the line will be drawn
+ start (Point): The starting point of the line
+ end (Point): The end point of the line
+ color (Color): The color of the line
+ thickness (int): The thickness of the line
+
+ Returns:
+ np.ndarray: The scene with the line drawn on it
+ """
+ cv2.line(
+ scene,
+ start.as_xy_int_tuple(),
+ end.as_xy_int_tuple(),
+ color.as_bgr(),
+ thickness=thickness,
+ )
+ returnscene
+
defdraw_rectangle(
+ scene:np.ndarray,rect:Rect,color:Color,thickness:int=2
+)->np.ndarray:
+"""
+ Draws a rectangle on an image.
+
+ Parameters:
+ scene (np.ndarray): The scene on which the rectangle will be drawn
+ rect (Rect): The rectangle to be drawn
+ color (Color): The color of the rectangle
+ thickness (int): The thickness of the rectangle border
+
+ Returns:
+ np.ndarray: The scene with the rectangle drawn on it
+ """
+ cv2.rectangle(
+ scene,
+ rect.top_left.as_xy_int_tuple(),
+ rect.bottom_right.as_xy_int_tuple(),
+ color.as_bgr(),
+ thickness=thickness,
+ )
+ returnscene
+
defdraw_filled_rectangle(scene:np.ndarray,rect:Rect,color:Color)->np.ndarray:
+"""
+ Draws a filled rectangle on an image.
+
+ Parameters:
+ scene (np.ndarray): The scene on which the rectangle will be drawn
+ rect (Rect): The rectangle to be drawn
+ color (Color): The color of the rectangle
+
+ Returns:
+ np.ndarray: The scene with the rectangle drawn on it
+ """
+ cv2.rectangle(
+ scene,
+ rect.top_left.as_xy_int_tuple(),
+ rect.bottom_right.as_xy_int_tuple(),
+ color.as_bgr(),
+ -1,
+ )
+ returnscene
+
defdraw_polygon(
+ scene:np.ndarray,polygon:np.ndarray,color:Color,thickness:int=2
+)->np.ndarray:
+"""Draw a polygon on a scene.
+
+ Parameters:
+ scene (np.ndarray): The scene to draw the polygon on.
+ polygon (np.ndarray): The polygon to be drawn, given as a list of vertices.
+ color (Color): The color of the polygon.
+ thickness (int, optional): The thickness of the polygon lines, by default 2.
+
+ Returns:
+ np.ndarray: The scene with the polygon drawn on it.
+ """
+ cv2.polylines(
+ scene,[polygon],isClosed=True,color=color.as_bgr(),thickness=thickness
+ )
+ returnscene
+
defdraw_text(
+ scene:np.ndarray,
+ text:str,
+ text_anchor:Point,
+ text_color:Color=Color.black(),
+ text_scale:float=0.5,
+ text_thickness:int=1,
+ text_padding:int=10,
+ text_font:int=cv2.FONT_HERSHEY_SIMPLEX,
+ background_color:Optional[Color]=None,
+)->np.ndarray:
+"""
+ Draw text with background on a scene.
+
+ Parameters:
+ scene (np.ndarray): A 2-dimensional numpy ndarray representing an image or scene.
+ text (str): The text to be drawn.
+ text_anchor (Point): The anchor point for the text, represented as a Point object with x and y attributes.
+ text_color (Color, optional): The color of the text. Defaults to black.
+ text_scale (float, optional): The scale of the text. Defaults to 0.5.
+ text_thickness (int, optional): The thickness of the text. Defaults to 1.
+ text_padding (int, optional): The amount of padding to add around the text when drawing a rectangle in the background. Defaults to 10.
+ text_font (int, optional): The font to use for the text. Defaults to cv2.FONT_HERSHEY_SIMPLEX.
+ background_color (Color, optional): The color of the background rectangle, if one is to be drawn. Defaults to None.
+
+ Returns:
+ np.ndarray: The input scene with the text drawn on it.
+
+ Examples:
+ ```python
+ >>> scene = np.zeros((100, 100, 3), dtype=np.uint8)
+ >>> text_anchor = Point(x=50, y=50)
+ >>> scene = draw_text(scene=scene, text="Hello, world!", text_anchor=text_anchor)
+ ```
+ """
+ text_width,text_height=cv2.getTextSize(
+ text=text,
+ fontFace=text_font,
+ fontScale=text_scale,
+ thickness=text_thickness,
+ )[0]
+ text_rect=Rect(
+ x=text_anchor.x-text_width//2,
+ y=text_anchor.y-text_height//2,
+ width=text_width,
+ height=text_height,
+ ).pad(text_padding)
+
+ ifbackground_colorisnotNone:
+ scene=draw_filled_rectangle(
+ scene=scene,rect=text_rect,color=background_color
+ )
+
+ cv2.putText(
+ img=scene,
+ text=text,
+ org=(text_anchor.x-text_width//2,text_anchor.y+text_height//2),
+ fontFace=text_font,
+ fontScale=text_scale,
+ color=text_color.as_bgr(),
+ thickness=text_thickness,
+ lineType=cv2.LINE_AA,
+ )
+ returnscene
+
Supervision is a set of easy-to-use utilities that will come in handy in any computer vision project.
+
Supervision is still in
+pre-release stage 🚧 Keep your eyes open for potential bugs and be aware that at this stage our API is still fluid and may change.
The advanced filtering capabilities of the Detections class offer users a versatile and efficient way to narrow down
+and refine object detections. This section outlines various filtering methods, including filtering by specific class
+or a set of classes, confidence, object area, bounding box area, relative area, box dimensions, and designated zones.
+Each method is demonstrated with concise code examples to provide users with a clear understanding of how to implement
+the filters in their applications.
Allows you to select detections based on their size. We define the area as the number of pixels occupied by the
+detection in the image. In the example below, we have sifted out the detections that are too small.
Allows you to select detections based on their size in relation to the size of whole image. Sometimes the concept of
+detection size changes depending on the image. Detection occupying 10000 square px can be large on a 1280x720 image
+but small on a 3840x2160 image. In such cases, we can filter out detections based on the percentage of the image area
+occupied by them. In the example below, we remove too large detections.
Allows you to select detections based on their dimensions. The size of the bounding box, as well as its coordinates,
+can be criteria for rejecting detection. Implementing such filtering requires a bit of custom code but is relatively
+simple and fast.
Allows you to use Detections in combination with PolygonZone to weed out bounding boxes that are in and out of the
+zone. In the example below you can see how to filter out all detections located in the lower part of the image.
Detections' greatest strength, however, is that you can build arbitrarily complex logical conditions by simply combining separate conditions using & or |.
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/search/search_index.json b/search/search_index.json
new file mode 100644
index 000000000..fbd33db10
--- /dev/null
+++ b/search/search_index.json
@@ -0,0 +1 @@
+{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Home","text":""},{"location":"#welcome","title":"\ud83d\udc4b Welcome","text":"
Supervision is a set of easy-to-use utilities that will come in handy in any computer vision project.
Supervision is still in pre-release stage \ud83d\udea7 Keep your eyes open for potential bugs and be aware that at this stage our API is still fluid and may change.
"},{"location":"#how-to-install","title":"\ud83d\udcbb How to Install","text":"
You can install supervision with pip in a 3.11>=Python>=3.7 environment.
See contributing section to know more about contributing to the project"},{"location":"changelog/","title":"Changelog","text":""},{"location":"changelog/#0100-june-14-2023","title":"0.10.0 June 14, 2023","text":"
Added [#125]: ability to load and save sv.ClassificationDataset in a folder structure format.
Added [#101]: ability to extract masks from YOLOv8 result using sv.Detections.from_yolov8. Here is an example illustrating how to extract boolean masks from the result of the YOLOv8 model inference.
Added [#122]: ability to crop image using sv.crop. Here is an example showing how to get a separate crop for each detection in sv.Detections.
Added [#120]: ability to conveniently save multiple images into directory using sv.ImageSink. Here is an example showing how to save every tenth video frame as a separate image.
>>> import supervision as sv\n\n>>> with sv.ImageSink(target_dir_path='target/directory/path') as sink:\n... for image in sv.get_video_frames_generator(source_path='source_video.mp4', stride=10):\n... sink.save_image(image=image)\n
Fixed [#106]: inconvenient handling of sv.PolygonZone coordinates. Now sv.PolygonZone accepts coordinates in the form of [[x1, y1], [x2, y2], ...] that can be both integers and floats.
"},{"location":"changelog/#080-may-17-2023","title":"0.8.0 May 17, 2023","text":"
Added [#100]: support for dataset inheritance. The current Dataset got renamed to DetectionDataset. Now DetectionDataset inherits from BaseDataset. This change was made to enforce the future consistency of APIs of different types of computer vision datasets.
Added [#100]: ability to save datasets in YOLO format using DetectionDataset.as_yolo.
Changed [#100]: default value of approximation_percentage parameter from 0.75 to 0.0 in DetectionDataset.as_yolo and DetectionDataset.as_pascal_voc.
"},{"location":"changelog/#070-may-11-2023","title":"0.7.0 May 11, 2023","text":"
Added [#91]: Detections.from_yolo_nas to enable seamless integration with YOLO-NAS model.
Added [#86]: ability to load datasets in YOLO format using Dataset.from_yolo.
Added [#84]: Detections.merge to merge multiple Detections objects together.
Fixed [#81]: LineZoneAnnotator.annotate does not return annotated frame.
Changed [#44]: LineZoneAnnotator.annotate to allow for custom text for the in and out tags.
"},{"location":"changelog/#060-april-19-2023","title":"0.6.0 April 19, 2023","text":"
Added [#71]: initial Dataset support and ability to save Detections in Pascal VOC XML format.
Added [#71]: new mask_to_polygons, filter_polygons_by_area, polygon_to_xyxy and approximate_polygon utilities.
Added [#72]: ability to load Pascal VOC XML object detections dataset as Dataset.
Changed [#70]: order of Detections attributes to make it consistent with order of objects in __iter__ tuple.
Changed [#71]: generate_2d_mask to polygon_to_mask.
"},{"location":"changelog/#052-april-13-2023","title":"0.5.2 April 13, 2023","text":"
Fixed [#63]: LineZone.trigger function expects 4 values instead of 5.
"},{"location":"changelog/#051-april-12-2023","title":"0.5.1 April 12, 2023","text":"
Fixed Detections.__getitem__ method did not return mask for selected item.
Fixed Detections.area crashed for mask detections.
"},{"location":"changelog/#050-april-10-2023","title":"0.5.0 April 10, 2023","text":"
Added [#58]: Detections.mask to enable segmentation support.
Added [#58]: MaskAnnotator to allow easy Detections.mask annotation.
Added [#58]: Detections.from_sam to enable native Segment Anything Model (SAM) support.
Changed [#58]: Detections.area behaviour to work not only with boxes but also with masks.
"},{"location":"changelog/#040-april-5-2023","title":"0.4.0 April 5, 2023","text":"
Added [#46]: Detections.empty to allow easy creation of empty Detections objects.
Added [#56]: Detections.from_roboflow to allow easy creation of Detections objects from Roboflow API inference results.
Added [#56]: plot_images_grid to allow easy plotting of multiple images on single plot.
Added [#56]: initial support for Pascal VOC XML format with detections_to_voc_xml method.
Changed [#56]: show_frame_in_notebook refactored and renamed to plot_image.
"},{"location":"changelog/#032-march-23-2023","title":"0.3.2 March 23, 2023","text":"
Changed [#50]: Allow Detections.class_id to be None.
"},{"location":"changelog/#031-march-6-2023","title":"0.3.1 March 6, 2023","text":"
Fixed [#41]: PolygonZone throws an exception when the object touches the bottom edge of the image.
Fixed [#42]: Detections.wth_nms method throws an exception when Detections is empty.
Changed [#36]: Detections.wth_nms support class agnostic and non-class agnostic case.
"},{"location":"changelog/#030-march-6-2023","title":"0.3.0 March 6, 2023","text":"
Changed: Allow Detections.confidence to be None.
Added: Detections.from_transformers and Detections.from_detectron2 to enable seamless integration with Transformers and Detectron2 models.
Added: Detections.area to dynamically calculate bounding box area.
Added: Detections.wth_nms to filter out double detections with NMS. Initial - only class agnostic - implementation.
"},{"location":"changelog/#020-february-2-2023","title":"0.2.0 February 2, 2023","text":"
Added: Advanced Detections filtering with pandas-like API.
Added: Detections.from_yolov5 and Detections.from_yolov8 to enable seamless integration with YOLOv5 and YOLOv8 models.
"},{"location":"changelog/#010-january-19-2023","title":"0.1.0 January 19, 2023","text":"
Say hello to Supervision \ud83d\udc4b
"},{"location":"classification/core/","title":"Core","text":""},{"location":"classification/core/#classifications","title":"Classifications","text":"Source code in supervision/classification/core.py
@dataclass\nclass Classifications:\n class_id: np.ndarray\n confidence: Optional[np.ndarray] = None\n\n def __post_init__(self) -> None:\n\"\"\"\n Validate the classification inputs.\n \"\"\"\n n = len(self.class_id)\n\n _validate_class_ids(self.class_id, n)\n _validate_confidence(self.confidence, n)\n\n @classmethod\n def from_yolov8(cls, yolov8_results) -> Classifications:\n\"\"\"\n Creates a Classifications instance from a [YOLOv8](https://github.com/ultralytics/ultralytics) inference result.\n\n Args:\n yolov8_results (ultralytics.yolo.engine.results.Results): The output Results instance from YOLOv8\n\n Returns:\n Detections: A new Classifications object.\n\n Example:\n ```python\n >>> import cv2\n >>> from ultralytics import YOLO\n >>> import supervision as sv\n\n >>> image = cv2.imread(SOURCE_IMAGE_PATH)\n >>> model = YOLO('yolov8s-cls.pt')\n >>> result = model(image)[0]\n >>> classifications = sv.Classifications.from_yolov8(result)\n ```\n \"\"\"\n confidence = yolov8_results.probs.data.cpu().numpy()\n return cls(class_id=np.arange(confidence.shape[0]), confidence=confidence)\n\n def get_top_k(self, k: int) -> Tuple[np.ndarray, np.ndarray]:\n\"\"\"\n Retrieve the top k class IDs and confidences, ordered in descending order by confidence.\n\n Args:\n k (int): The number of top class IDs and confidences to retrieve.\n\n Returns:\n Tuple[np.ndarray, np.ndarray]: A tuple containing the top k class IDs and confidences.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> classifications = sv.Classifications(...)\n\n >>> classifications.get_top_k(1)\n\n (array([1]), array([0.9]))\n ```\n \"\"\"\n if self.confidence is None:\n raise ValueError(\"top_k could not be calculated, confidence is None\")\n\n order = np.argsort(self.confidence)[::-1]\n top_k_order = order[:k]\n top_k_class_id = self.class_id[top_k_order]\n top_k_confidence = self.confidence[top_k_order]\n\n return top_k_class_id, top_k_confidence\n
Retrieve the top k class IDs and confidences, ordered in descending order by confidence.
Parameters:
Name Type Description Default kint
The number of top class IDs and confidences to retrieve.
required
Returns:
Type Description Tuple[np.ndarray, np.ndarray]
Tuple[np.ndarray, np.ndarray]: A tuple containing the top k class IDs and confidences.
Example
>>> import supervision as sv\n\n>>> classifications = sv.Classifications(...)\n\n>>> classifications.get_top_k(1)\n\n(array([1]), array([0.9]))\n
Source code in supervision/classification/core.py
def get_top_k(self, k: int) -> Tuple[np.ndarray, np.ndarray]:\n\"\"\"\n Retrieve the top k class IDs and confidences, ordered in descending order by confidence.\n\n Args:\n k (int): The number of top class IDs and confidences to retrieve.\n\n Returns:\n Tuple[np.ndarray, np.ndarray]: A tuple containing the top k class IDs and confidences.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> classifications = sv.Classifications(...)\n\n >>> classifications.get_top_k(1)\n\n (array([1]), array([0.9]))\n ```\n \"\"\"\n if self.confidence is None:\n raise ValueError(\"top_k could not be calculated, confidence is None\")\n\n order = np.argsort(self.confidence)[::-1]\n top_k_order = order[:k]\n top_k_class_id = self.class_id[top_k_order]\n top_k_confidence = self.confidence[top_k_order]\n\n return top_k_class_id, top_k_confidence\n
Dataset API is still fluid and may change. If you use Dataset API in your project until further notice, freeze the supervision version in your requirements.txt or setup.py.
Dataclass containing information about object detection dataset.
Attributes:
Name Type Description classesList[str]
List containing dataset class names.
imagesDict[str, np.ndarray]
Dictionary mapping image name to image.
annotationsDict[str, Detections]
Dictionary mapping image name to annotations.
Source code in supervision/dataset/core.py
@dataclass\nclass DetectionDataset(BaseDataset):\n\"\"\"\n Dataclass containing information about object detection dataset.\n\n Attributes:\n classes (List[str]): List containing dataset class names.\n images (Dict[str, np.ndarray]): Dictionary mapping image name to image.\n annotations (Dict[str, Detections]): Dictionary mapping image name to annotations.\n \"\"\"\n\n classes: List[str]\n images: Dict[str, np.ndarray]\n annotations: Dict[str, Detections]\n\n def __len__(self) -> int:\n\"\"\"\n Return the number of images in the dataset.\n\n Returns:\n int: The number of images.\n \"\"\"\n return len(self.images)\n\n def __iter__(self) -> Iterator[Tuple[str, np.ndarray, Detections]]:\n\"\"\"\n Iterate over the images and annotations in the dataset.\n\n Yields:\n Iterator[Tuple[str, np.ndarray, Detections]]: An iterator that yields tuples containing the image name,\n the image data, and its corresponding annotation.\n \"\"\"\n for image_name, image in self.images.items():\n yield image_name, image, self.annotations.get(image_name, None)\n\n def split(\n self, split_ratio=0.8, random_state=None, shuffle: bool = True\n ) -> Tuple[DetectionDataset, DetectionDataset]:\n\"\"\"\n Splits the dataset into two parts (training and testing) using the provided split_ratio.\n\n Args:\n split_ratio (float, optional): The ratio of the training set to the entire dataset.\n random_state (int, optional): The seed for the random number generator. This is used for reproducibility.\n shuffle (bool, optional): Whether to shuffle the data before splitting.\n\n Returns:\n Tuple[DetectionDataset, DetectionDataset]: A tuple containing the training and testing datasets.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> ds = sv.DetectionDataset(...)\n >>> train_ds, test_ds = ds.split(split_ratio=0.7, random_state=42, shuffle=True)\n >>> len(train_ds), len(test_ds)\n (700, 300)\n ```\n \"\"\"\n\n image_names = list(self.images.keys())\n train_names, test_names = train_test_split(\n data=image_names,\n train_ratio=split_ratio,\n random_state=random_state,\n shuffle=shuffle,\n )\n\n train_dataset = DetectionDataset(\n classes=self.classes,\n images={name: self.images[name] for name in train_names},\n annotations={name: self.annotations[name] for name in train_names},\n )\n test_dataset = DetectionDataset(\n classes=self.classes,\n images={name: self.images[name] for name in test_names},\n annotations={name: self.annotations[name] for name in test_names},\n )\n return train_dataset, test_dataset\n\n def as_pascal_voc(\n self,\n images_directory_path: Optional[str] = None,\n annotations_directory_path: Optional[str] = None,\n min_image_area_percentage: float = 0.0,\n max_image_area_percentage: float = 1.0,\n approximation_percentage: float = 0.0,\n ) -> None:\n\"\"\"\n Exports the dataset to PASCAL VOC format. This method saves the images and their corresponding annotations in\n PASCAL VOC format, which consists of XML files. The method allows filtering the detections based on their area\n percentage.\n\n Args:\n images_directory_path (Optional[str]): The path to the directory where the images should be saved.\n If not provided, images will not be saved.\n annotations_directory_path (Optional[str]): The path to the directory where the annotations in\n PASCAL VOC format should be saved. If not provided, annotations will not be saved.\n min_image_area_percentage (float): The minimum percentage of detection area relative to\n the image area for a detection to be included.\n max_image_area_percentage (float): The maximum percentage of detection area relative to\n the image area for a detection to be included.\n approximation_percentage (float): The percentage of polygon points to be removed from the input polygon, in the range [0, 1).\n \"\"\"\n if images_directory_path:\n images_path = Path(images_directory_path)\n images_path.mkdir(parents=True, exist_ok=True)\n\n if annotations_directory_path:\n annotations_path = Path(annotations_directory_path)\n annotations_path.mkdir(parents=True, exist_ok=True)\n\n for image_name, image in self.images.items():\n detections = self.annotations[image_name]\n\n if images_directory_path:\n cv2.imwrite(str(images_path / image_name), image)\n\n if annotations_directory_path:\n annotation_name = Path(image_name).stem\n pascal_voc_xml = detections_to_pascal_voc(\n detections=detections,\n classes=self.classes,\n filename=image_name,\n image_shape=image.shape,\n min_image_area_percentage=min_image_area_percentage,\n max_image_area_percentage=max_image_area_percentage,\n approximation_percentage=approximation_percentage,\n )\n\n with open(annotations_path / f\"{annotation_name}.xml\", \"w\") as f:\n f.write(pascal_voc_xml)\n\n @classmethod\n def from_pascal_voc(\n cls, images_directory_path: str, annotations_directory_path: str\n ) -> DetectionDataset:\n\"\"\"\n Creates a Dataset instance from PASCAL VOC formatted data.\n\n Args:\n images_directory_path (str): The path to the directory containing the images.\n annotations_directory_path (str): The path to the directory containing the PASCAL VOC XML annotations.\n\n Returns:\n DetectionDataset: A DetectionDataset instance containing the loaded images and annotations.\n\n Example:\n ```python\n >>> import roboflow\n >>> from roboflow import Roboflow\n >>> import supervision as sv\n\n >>> roboflow.login()\n\n >>> rf = Roboflow()\n\n >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)\n >>> dataset = project.version(PROJECT_VERSION).download(\"voc\")\n\n >>> ds = sv.DetectionDataset.from_yolo(\n ... images_directory_path=f\"{dataset.location}/train/images\",\n ... annotations_directory_path=f\"{dataset.location}/train/labels\"\n ... )\n\n >>> ds.classes\n ['dog', 'person']\n ```\n \"\"\"\n image_paths = list_files_with_extensions(\n directory=images_directory_path, extensions=[\"jpg\", \"jpeg\", \"png\"]\n )\n annotation_paths = list_files_with_extensions(\n directory=annotations_directory_path, extensions=[\"xml\"]\n )\n\n raw_annotations: List[Tuple[str, Detections, List[str]]] = [\n load_pascal_voc_annotations(annotation_path=str(annotation_path))\n for annotation_path in annotation_paths\n ]\n\n classes = []\n for annotation in raw_annotations:\n classes.extend(annotation[2])\n classes = list(set(classes))\n\n for annotation in raw_annotations:\n class_id = [classes.index(class_name) for class_name in annotation[2]]\n annotation[1].class_id = np.array(class_id)\n\n images = {\n image_path.name: cv2.imread(str(image_path)) for image_path in image_paths\n }\n\n annotations = {\n image_name: detections for image_name, detections, _ in raw_annotations\n }\n return DetectionDataset(classes=classes, images=images, annotations=annotations)\n\n @classmethod\n def from_yolo(\n cls,\n images_directory_path: str,\n annotations_directory_path: str,\n data_yaml_path: str,\n force_masks: bool = False,\n ) -> DetectionDataset:\n\"\"\"\n Creates a Dataset instance from YOLO formatted data.\n\n Args:\n images_directory_path (str): The path to the directory containing the images.\n annotations_directory_path (str): The path to the directory containing the YOLO annotation files.\n data_yaml_path (str): The path to the data YAML file containing class information.\n force_masks (bool, optional): If True, forces masks to be loaded for all annotations, regardless of whether they are present.\n\n Returns:\n DetectionDataset: A DetectionDataset instance containing the loaded images and annotations.\n\n Example:\n ```python\n >>> import roboflow\n >>> from roboflow import Roboflow\n >>> import supervision as sv\n\n >>> roboflow.login()\n\n >>> rf = Roboflow()\n\n >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)\n >>> dataset = project.version(PROJECT_VERSION).download(\"yolov5\")\n\n >>> ds = sv.DetectionDataset.from_yolo(\n ... images_directory_path=f\"{dataset.location}/train/images\",\n ... annotations_directory_path=f\"{dataset.location}/train/labels\",\n ... data_yaml_path=f\"{dataset.location}/data.yaml\"\n ... )\n\n >>> ds.classes\n ['dog', 'person']\n ```\n \"\"\"\n classes, images, annotations = load_yolo_annotations(\n images_directory_path=images_directory_path,\n annotations_directory_path=annotations_directory_path,\n data_yaml_path=data_yaml_path,\n force_masks=force_masks,\n )\n return DetectionDataset(classes=classes, images=images, annotations=annotations)\n\n def as_yolo(\n self,\n images_directory_path: Optional[str] = None,\n annotations_directory_path: Optional[str] = None,\n data_yaml_path: Optional[str] = None,\n min_image_area_percentage: float = 0.0,\n max_image_area_percentage: float = 1.0,\n approximation_percentage: float = 0.0,\n ) -> None:\n\"\"\"\n Exports the dataset to YOLO format. This method saves the images and their corresponding\n annotations in YOLO format, which is a simple text file that describes an object in the image. It also allows\n for the optional saving of a data.yaml file, used in YOLOv5, that contains metadata about the dataset.\n\n The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.\n\n Args:\n images_directory_path (Optional[str]): The path to the directory where the images should be saved.\n If not provided, images will not be saved.\n annotations_directory_path (Optional[str]): The path to the directory where the annotations in\n YOLO format should be saved. If not provided, annotations will not be saved.\n data_yaml_path (Optional[str]): The path where the data.yaml file should be saved.\n If not provided, the file will not be saved.\n min_image_area_percentage (float): The minimum percentage of detection area relative to\n the image area for a detection to be included.\n max_image_area_percentage (float): The maximum percentage of detection area relative to\n the image area for a detection to be included.\n approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,\n in the range [0, 1). This is useful for simplifying the annotations.\n \"\"\"\n if images_directory_path is not None:\n save_dataset_images(\n images_directory_path=images_directory_path, images=self.images\n )\n if annotations_directory_path is not None:\n save_yolo_annotations(\n annotations_directory_path=annotations_directory_path,\n images=self.images,\n annotations=self.annotations,\n min_image_area_percentage=min_image_area_percentage,\n max_image_area_percentage=max_image_area_percentage,\n approximation_percentage=approximation_percentage,\n )\n if data_yaml_path is not None:\n save_data_yaml(data_yaml_path=data_yaml_path, classes=self.classes)\n\n @classmethod\n def from_coco(\n cls,\n images_directory_path: str,\n annotations_path: str,\n force_masks: bool = False,\n ) -> DetectionDataset:\n\"\"\"\n Creates a Dataset instance from YOLO formatted data.\n\n Args:\n images_directory_path (str): The path to the directory containing the images.\n annotations_path (str): The path to the json annotation files.\n force_masks (bool, optional): If True, forces masks to be loaded for all annotations, regardless of whether they are present.\n\n Returns:\n DetectionDataset: A DetectionDataset instance containing the loaded images and annotations.\n\n Example:\n ```python\n >>> import roboflow\n >>> from roboflow import Roboflow\n >>> import supervision as sv\n\n >>> roboflow.login()\n\n >>> rf = Roboflow()\n\n >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)\n >>> dataset = project.version(PROJECT_VERSION).download(\"coco\")\n\n >>> ds = sv.DetectionDataset.from_coco(\n ... images_directory_path=f\"{dataset.location}/train\",\n ... annotations_path=f\"{dataset.location}/train/_annotations.coco.json\",\n ... )\n\n >>> ds.classes\n ['dog', 'person']\n ```\n \"\"\"\n classes, images, annotations = load_coco_annotations(\n images_directory_path=images_directory_path,\n annotations_path=annotations_path,\n force_masks=force_masks,\n )\n return DetectionDataset(classes=classes, images=images, annotations=annotations)\n\n def as_coco(\n self,\n images_directory_path: Optional[str] = None,\n annotations_path: Optional[str] = None,\n min_image_area_percentage: float = 0.0,\n max_image_area_percentage: float = 1.0,\n approximation_percentage: float = 0.0,\n licenses: Optional[list] = None,\n info: Optional[dict] = None,\n ) -> None:\n\"\"\"\n Exports the dataset to COCO format. This method saves the images and their corresponding\n annotations in COCO format, which is a simple json file that describes an object in the image.\n Annotation json file also include category maps.\n\n The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.\n\n Args:\n images_directory_path (Optional[str]): The path to the directory where the images should be saved.\n If not provided, images will not be saved.\n annotations_directory_path (Optional[str]): The path to the directory where the annotations in\n YOLO format should be saved. If not provided, annotations will not be saved.\n min_image_area_percentage (float): The minimum percentage of detection area relative to\n the image area for a detection to be included.\n max_image_area_percentage (float): The maximum percentage of detection area relative to\n the image area for a detection to be included.\n approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,\n in the range [0, 1). This is useful for simplifying the annotations.\n licenses (Optional[str]): List of licenses for images\n info (Optional[dict]): Information of Dataset as dictionary\n \"\"\"\n if images_directory_path is not None:\n save_dataset_images(\n images_directory_path=images_directory_path, images=self.images\n )\n if annotations_path is not None:\n save_coco_annotations(\n annotation_path=annotations_path,\n images=self.images,\n annotations=self.annotations,\n classes=self.classes,\n min_image_area_percentage=min_image_area_percentage,\n max_image_area_percentage=max_image_area_percentage,\n approximation_percentage=approximation_percentage,\n licenses=licenses,\n info=info,\n )\n
Iterate over the images and annotations in the dataset.
Yields:
Type Description str
Iterator[Tuple[str, np.ndarray, Detections]]: An iterator that yields tuples containing the image name, the image data, and its corresponding annotation.
Source code in supervision/dataset/core.py
def __iter__(self) -> Iterator[Tuple[str, np.ndarray, Detections]]:\n\"\"\"\n Iterate over the images and annotations in the dataset.\n\n Yields:\n Iterator[Tuple[str, np.ndarray, Detections]]: An iterator that yields tuples containing the image name,\n the image data, and its corresponding annotation.\n \"\"\"\n for image_name, image in self.images.items():\n yield image_name, image, self.annotations.get(image_name, None)\n
def __len__(self) -> int:\n\"\"\"\n Return the number of images in the dataset.\n\n Returns:\n int: The number of images.\n \"\"\"\n return len(self.images)\n
Exports the dataset to COCO format. This method saves the images and their corresponding annotations in COCO format, which is a simple json file that describes an object in the image. Annotation json file also include category maps.
The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
Parameters:
Name Type Description Default images_directory_pathOptional[str]
The path to the directory where the images should be saved. If not provided, images will not be saved.
Noneannotations_directory_pathOptional[str]
The path to the directory where the annotations in YOLO format should be saved. If not provided, annotations will not be saved.
required min_image_area_percentagefloat
The minimum percentage of detection area relative to the image area for a detection to be included.
0.0max_image_area_percentagefloat
The maximum percentage of detection area relative to the image area for a detection to be included.
1.0approximation_percentagefloat
The percentage of polygon points to be removed from the input polygon, in the range [0, 1). This is useful for simplifying the annotations.
0.0licensesOptional[str]
List of licenses for images
NoneinfoOptional[dict]
Information of Dataset as dictionary
None Source code in supervision/dataset/core.py
def as_coco(\n self,\n images_directory_path: Optional[str] = None,\n annotations_path: Optional[str] = None,\n min_image_area_percentage: float = 0.0,\n max_image_area_percentage: float = 1.0,\n approximation_percentage: float = 0.0,\n licenses: Optional[list] = None,\n info: Optional[dict] = None,\n) -> None:\n\"\"\"\n Exports the dataset to COCO format. This method saves the images and their corresponding\n annotations in COCO format, which is a simple json file that describes an object in the image.\n Annotation json file also include category maps.\n\n The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.\n\n Args:\n images_directory_path (Optional[str]): The path to the directory where the images should be saved.\n If not provided, images will not be saved.\n annotations_directory_path (Optional[str]): The path to the directory where the annotations in\n YOLO format should be saved. If not provided, annotations will not be saved.\n min_image_area_percentage (float): The minimum percentage of detection area relative to\n the image area for a detection to be included.\n max_image_area_percentage (float): The maximum percentage of detection area relative to\n the image area for a detection to be included.\n approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,\n in the range [0, 1). This is useful for simplifying the annotations.\n licenses (Optional[str]): List of licenses for images\n info (Optional[dict]): Information of Dataset as dictionary\n \"\"\"\n if images_directory_path is not None:\n save_dataset_images(\n images_directory_path=images_directory_path, images=self.images\n )\n if annotations_path is not None:\n save_coco_annotations(\n annotation_path=annotations_path,\n images=self.images,\n annotations=self.annotations,\n classes=self.classes,\n min_image_area_percentage=min_image_area_percentage,\n max_image_area_percentage=max_image_area_percentage,\n approximation_percentage=approximation_percentage,\n licenses=licenses,\n info=info,\n )\n
Exports the dataset to PASCAL VOC format. This method saves the images and their corresponding annotations in PASCAL VOC format, which consists of XML files. The method allows filtering the detections based on their area percentage.
Parameters:
Name Type Description Default images_directory_pathOptional[str]
The path to the directory where the images should be saved. If not provided, images will not be saved.
Noneannotations_directory_pathOptional[str]
The path to the directory where the annotations in PASCAL VOC format should be saved. If not provided, annotations will not be saved.
Nonemin_image_area_percentagefloat
The minimum percentage of detection area relative to the image area for a detection to be included.
0.0max_image_area_percentagefloat
The maximum percentage of detection area relative to the image area for a detection to be included.
1.0approximation_percentagefloat
The percentage of polygon points to be removed from the input polygon, in the range [0, 1).
0.0 Source code in supervision/dataset/core.py
def as_pascal_voc(\n self,\n images_directory_path: Optional[str] = None,\n annotations_directory_path: Optional[str] = None,\n min_image_area_percentage: float = 0.0,\n max_image_area_percentage: float = 1.0,\n approximation_percentage: float = 0.0,\n) -> None:\n\"\"\"\n Exports the dataset to PASCAL VOC format. This method saves the images and their corresponding annotations in\n PASCAL VOC format, which consists of XML files. The method allows filtering the detections based on their area\n percentage.\n\n Args:\n images_directory_path (Optional[str]): The path to the directory where the images should be saved.\n If not provided, images will not be saved.\n annotations_directory_path (Optional[str]): The path to the directory where the annotations in\n PASCAL VOC format should be saved. If not provided, annotations will not be saved.\n min_image_area_percentage (float): The minimum percentage of detection area relative to\n the image area for a detection to be included.\n max_image_area_percentage (float): The maximum percentage of detection area relative to\n the image area for a detection to be included.\n approximation_percentage (float): The percentage of polygon points to be removed from the input polygon, in the range [0, 1).\n \"\"\"\n if images_directory_path:\n images_path = Path(images_directory_path)\n images_path.mkdir(parents=True, exist_ok=True)\n\n if annotations_directory_path:\n annotations_path = Path(annotations_directory_path)\n annotations_path.mkdir(parents=True, exist_ok=True)\n\n for image_name, image in self.images.items():\n detections = self.annotations[image_name]\n\n if images_directory_path:\n cv2.imwrite(str(images_path / image_name), image)\n\n if annotations_directory_path:\n annotation_name = Path(image_name).stem\n pascal_voc_xml = detections_to_pascal_voc(\n detections=detections,\n classes=self.classes,\n filename=image_name,\n image_shape=image.shape,\n min_image_area_percentage=min_image_area_percentage,\n max_image_area_percentage=max_image_area_percentage,\n approximation_percentage=approximation_percentage,\n )\n\n with open(annotations_path / f\"{annotation_name}.xml\", \"w\") as f:\n f.write(pascal_voc_xml)\n
Exports the dataset to YOLO format. This method saves the images and their corresponding annotations in YOLO format, which is a simple text file that describes an object in the image. It also allows for the optional saving of a data.yaml file, used in YOLOv5, that contains metadata about the dataset.
The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.
Parameters:
Name Type Description Default images_directory_pathOptional[str]
The path to the directory where the images should be saved. If not provided, images will not be saved.
Noneannotations_directory_pathOptional[str]
The path to the directory where the annotations in YOLO format should be saved. If not provided, annotations will not be saved.
Nonedata_yaml_pathOptional[str]
The path where the data.yaml file should be saved. If not provided, the file will not be saved.
Nonemin_image_area_percentagefloat
The minimum percentage of detection area relative to the image area for a detection to be included.
0.0max_image_area_percentagefloat
The maximum percentage of detection area relative to the image area for a detection to be included.
1.0approximation_percentagefloat
The percentage of polygon points to be removed from the input polygon, in the range [0, 1). This is useful for simplifying the annotations.
0.0 Source code in supervision/dataset/core.py
def as_yolo(\n self,\n images_directory_path: Optional[str] = None,\n annotations_directory_path: Optional[str] = None,\n data_yaml_path: Optional[str] = None,\n min_image_area_percentage: float = 0.0,\n max_image_area_percentage: float = 1.0,\n approximation_percentage: float = 0.0,\n) -> None:\n\"\"\"\n Exports the dataset to YOLO format. This method saves the images and their corresponding\n annotations in YOLO format, which is a simple text file that describes an object in the image. It also allows\n for the optional saving of a data.yaml file, used in YOLOv5, that contains metadata about the dataset.\n\n The method allows filtering the detections based on their area percentage and offers an option for polygon approximation.\n\n Args:\n images_directory_path (Optional[str]): The path to the directory where the images should be saved.\n If not provided, images will not be saved.\n annotations_directory_path (Optional[str]): The path to the directory where the annotations in\n YOLO format should be saved. If not provided, annotations will not be saved.\n data_yaml_path (Optional[str]): The path where the data.yaml file should be saved.\n If not provided, the file will not be saved.\n min_image_area_percentage (float): The minimum percentage of detection area relative to\n the image area for a detection to be included.\n max_image_area_percentage (float): The maximum percentage of detection area relative to\n the image area for a detection to be included.\n approximation_percentage (float): The percentage of polygon points to be removed from the input polygon,\n in the range [0, 1). This is useful for simplifying the annotations.\n \"\"\"\n if images_directory_path is not None:\n save_dataset_images(\n images_directory_path=images_directory_path, images=self.images\n )\n if annotations_directory_path is not None:\n save_yolo_annotations(\n annotations_directory_path=annotations_directory_path,\n images=self.images,\n annotations=self.annotations,\n min_image_area_percentage=min_image_area_percentage,\n max_image_area_percentage=max_image_area_percentage,\n approximation_percentage=approximation_percentage,\n )\n if data_yaml_path is not None:\n save_data_yaml(data_yaml_path=data_yaml_path, classes=self.classes)\n
def split(\n self, split_ratio=0.8, random_state=None, shuffle: bool = True\n) -> Tuple[DetectionDataset, DetectionDataset]:\n\"\"\"\n Splits the dataset into two parts (training and testing) using the provided split_ratio.\n\n Args:\n split_ratio (float, optional): The ratio of the training set to the entire dataset.\n random_state (int, optional): The seed for the random number generator. This is used for reproducibility.\n shuffle (bool, optional): Whether to shuffle the data before splitting.\n\n Returns:\n Tuple[DetectionDataset, DetectionDataset]: A tuple containing the training and testing datasets.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> ds = sv.DetectionDataset(...)\n >>> train_ds, test_ds = ds.split(split_ratio=0.7, random_state=42, shuffle=True)\n >>> len(train_ds), len(test_ds)\n (700, 300)\n ```\n \"\"\"\n\n image_names = list(self.images.keys())\n train_names, test_names = train_test_split(\n data=image_names,\n train_ratio=split_ratio,\n random_state=random_state,\n shuffle=shuffle,\n )\n\n train_dataset = DetectionDataset(\n classes=self.classes,\n images={name: self.images[name] for name in train_names},\n annotations={name: self.annotations[name] for name in train_names},\n )\n test_dataset = DetectionDataset(\n classes=self.classes,\n images={name: self.images[name] for name in test_names},\n annotations={name: self.annotations[name] for name in test_names},\n )\n return train_dataset, test_dataset\n
Dataclass containing information about a classification dataset.
Attributes:
Name Type Description classesList[str]
List containing dataset class names.
imagesDict[str, np.ndarray]
Dictionary mapping image name to image.
annotationsDict[str, Detections]
Dictionary mapping image name to annotations.
Source code in supervision/dataset/core.py
@dataclass\nclass ClassificationDataset(BaseDataset):\n\"\"\"\n Dataclass containing information about a classification dataset.\n\n Attributes:\n classes (List[str]): List containing dataset class names.\n images (Dict[str, np.ndarray]): Dictionary mapping image name to image.\n annotations (Dict[str, Detections]): Dictionary mapping image name to annotations.\n \"\"\"\n\n classes: List[str]\n images: Dict[str, np.ndarray]\n annotations: Dict[str, Classifications]\n\n def __len__(self) -> int:\n return len(self.images)\n\n def split(\n self, split_ratio=0.8, random_state=None, shuffle: bool = True\n ) -> Tuple[ClassificationDataset, ClassificationDataset]:\n\"\"\"\n Splits the dataset into two parts (training and testing) using the provided split_ratio.\n\n Args:\n split_ratio (float, optional): The ratio of the training set to the entire dataset.\n random_state (int, optional): The seed for the random number generator. This is used for reproducibility.\n shuffle (bool, optional): Whether to shuffle the data before splitting.\n\n Returns:\n Tuple[ClassificationDataset, ClassificationDataset]: A tuple containing the training and testing datasets.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> cd = sv.ClassificationDataset(...)\n >>> train_cd, test_cd = cd.split(split_ratio=0.7, random_state=42, shuffle=True)\n >>> len(train_cd), len(test_cd)\n (700, 300)\n ```\n \"\"\"\n image_names = list(self.images.keys())\n train_names, test_names = train_test_split(\n data=image_names,\n train_ratio=split_ratio,\n random_state=random_state,\n shuffle=shuffle,\n )\n\n train_dataset = ClassificationDataset(\n classes=self.classes,\n images={name: self.images[name] for name in train_names},\n annotations={name: self.annotations[name] for name in train_names},\n )\n test_dataset = ClassificationDataset(\n classes=self.classes,\n images={name: self.images[name] for name in test_names},\n annotations={name: self.annotations[name] for name in test_names},\n )\n return train_dataset, test_dataset\n\n def as_folder_structure(self, root_directory_path: str) -> None:\n\"\"\"\n Saves the dataset as a multi-class folder structure.\n\n Args:\n root_directory_path (str): The path to the directory where the dataset will be saved.\n \"\"\"\n os.makedirs(root_directory_path, exist_ok=True)\n\n for class_name in self.classes:\n os.makedirs(os.path.join(root_directory_path, class_name), exist_ok=True)\n\n for image_name in self.images:\n classification = self.annotations[image_name]\n image = self.images[image_name]\n class_id = (\n classification.class_id[0]\n if classification.confidence is None\n else classification.get_top_k(1)[0]\n )\n class_name = self.classes[class_id]\n image_path = os.path.join(root_directory_path, class_name, image_name)\n cv2.imwrite(image_path, image)\n\n @classmethod\n def from_folder_structure(cls, root_directory_path: str) -> ClassificationDataset:\n\"\"\"\n Load data from a multiclass folder structure into a ClassificationDataset.\n\n Args:\n root_directory_path (str): The path to the dataset directory.\n\n Returns:\n ClassificationDataset: The dataset.\n\n Example:\n ```python\n >>> import roboflow\n >>> from roboflow import Roboflow\n >>> import supervision as sv\n\n >>> roboflow.login()\n\n >>> rf = Roboflow()\n\n >>> project = rf.workspace(WORKSPACE_ID).project(PROJECT_ID)\n >>> dataset = project.version(PROJECT_VERSION).download(\"folder\")\n\n >>> cd = sv.ClassificationDataset.from_folder_structure(\n ... root_directory_path=f\"{dataset.location}/train\"\n ... )\n ```\n \"\"\"\n classes = os.listdir(root_directory_path)\n classes = sorted(set(classes))\n\n images = {}\n annotations = {}\n\n for class_name in classes:\n class_id = classes.index(class_name)\n\n for image in os.listdir(os.path.join(root_directory_path, class_name)):\n image_dir = os.path.join(root_directory_path, class_name, image)\n images[image] = cv2.imread(image_dir)\n annotations[image] = Classifications(\n class_id=np.array([class_id]),\n )\n\n return cls(\n classes=classes,\n images=images,\n annotations=annotations,\n )\n
Saves the dataset as a multi-class folder structure.
Parameters:
Name Type Description Default root_directory_pathstr
The path to the directory where the dataset will be saved.
required Source code in supervision/dataset/core.py
def as_folder_structure(self, root_directory_path: str) -> None:\n\"\"\"\n Saves the dataset as a multi-class folder structure.\n\n Args:\n root_directory_path (str): The path to the directory where the dataset will be saved.\n \"\"\"\n os.makedirs(root_directory_path, exist_ok=True)\n\n for class_name in self.classes:\n os.makedirs(os.path.join(root_directory_path, class_name), exist_ok=True)\n\n for image_name in self.images:\n classification = self.annotations[image_name]\n image = self.images[image_name]\n class_id = (\n classification.class_id[0]\n if classification.confidence is None\n else classification.get_top_k(1)[0]\n )\n class_name = self.classes[class_id]\n image_path = os.path.join(root_directory_path, class_name, image_name)\n cv2.imwrite(image_path, image)\n
Splits the dataset into two parts (training and testing) using the provided split_ratio.
Parameters:
Name Type Description Default split_ratiofloat
The ratio of the training set to the entire dataset.
0.8random_stateint
The seed for the random number generator. This is used for reproducibility.
Noneshufflebool
Whether to shuffle the data before splitting.
True
Returns:
Type Description Tuple[ClassificationDataset, ClassificationDataset]
Tuple[ClassificationDataset, ClassificationDataset]: A tuple containing the training and testing datasets.
Example
>>> import supervision as sv\n\n>>> cd = sv.ClassificationDataset(...)\n>>> train_cd, test_cd = cd.split(split_ratio=0.7, random_state=42, shuffle=True)\n>>> len(train_cd), len(test_cd)\n(700, 300)\n
Source code in supervision/dataset/core.py
def split(\n self, split_ratio=0.8, random_state=None, shuffle: bool = True\n) -> Tuple[ClassificationDataset, ClassificationDataset]:\n\"\"\"\n Splits the dataset into two parts (training and testing) using the provided split_ratio.\n\n Args:\n split_ratio (float, optional): The ratio of the training set to the entire dataset.\n random_state (int, optional): The seed for the random number generator. This is used for reproducibility.\n shuffle (bool, optional): Whether to shuffle the data before splitting.\n\n Returns:\n Tuple[ClassificationDataset, ClassificationDataset]: A tuple containing the training and testing datasets.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> cd = sv.ClassificationDataset(...)\n >>> train_cd, test_cd = cd.split(split_ratio=0.7, random_state=42, shuffle=True)\n >>> len(train_cd), len(test_cd)\n (700, 300)\n ```\n \"\"\"\n image_names = list(self.images.keys())\n train_names, test_names = train_test_split(\n data=image_names,\n train_ratio=split_ratio,\n random_state=random_state,\n shuffle=shuffle,\n )\n\n train_dataset = ClassificationDataset(\n classes=self.classes,\n images={name: self.images[name] for name in train_names},\n annotations={name: self.annotations[name] for name in train_names},\n )\n test_dataset = ClassificationDataset(\n classes=self.classes,\n images={name: self.images[name] for name in test_names},\n annotations={name: self.annotations[name] for name in test_names},\n )\n return train_dataset, test_dataset\n
A class for drawing bounding boxes on an image using detections provided.
Attributes:
Name Type Description colorUnion[Color, ColorPalette]
The color to draw the bounding box, can be a single color or a color palette
thicknessint
The thickness of the bounding box lines, default is 2
text_colorColor
The color of the text on the bounding box, default is white
text_scalefloat
The scale of the text on the bounding box, default is 0.5
text_thicknessint
The thickness of the text on the bounding box, default is 1
text_paddingint
The padding around the text on the bounding box, default is 5
Source code in supervision/detection/annotate.py
class BoxAnnotator:\n\"\"\"\n A class for drawing bounding boxes on an image using detections provided.\n\n Attributes:\n color (Union[Color, ColorPalette]): The color to draw the bounding box, can be a single color or a color palette\n thickness (int): The thickness of the bounding box lines, default is 2\n text_color (Color): The color of the text on the bounding box, default is white\n text_scale (float): The scale of the text on the bounding box, default is 0.5\n text_thickness (int): The thickness of the text on the bounding box, default is 1\n text_padding (int): The padding around the text on the bounding box, default is 5\n\n \"\"\"\n\n def __init__(\n self,\n color: Union[Color, ColorPalette] = ColorPalette.default(),\n thickness: int = 2,\n text_color: Color = Color.black(),\n text_scale: float = 0.5,\n text_thickness: int = 1,\n text_padding: int = 10,\n ):\n self.color: Union[Color, ColorPalette] = color\n self.thickness: int = thickness\n self.text_color: Color = text_color\n self.text_scale: float = text_scale\n self.text_thickness: int = text_thickness\n self.text_padding: int = text_padding\n\n def annotate(\n self,\n scene: np.ndarray,\n detections: Detections,\n labels: Optional[List[str]] = None,\n skip_label: bool = False,\n ) -> np.ndarray:\n\"\"\"\n Draws bounding boxes on the frame using the detections provided.\n\n Args:\n scene (np.ndarray): The image on which the bounding boxes will be drawn\n detections (Detections): The detections for which the bounding boxes will be drawn\n labels (Optional[List[str]]): An optional list of labels corresponding to each detection. If `labels` are not provided, corresponding `class_id` will be used as label.\n skip_label (bool): Is set to `True`, skips bounding box label annotation.\n Returns:\n np.ndarray: The image with the bounding boxes drawn on it\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> classes = ['person', ...]\n >>> image = ...\n >>> detections = sv.Detections(...)\n\n >>> box_annotator = sv.BoxAnnotator()\n >>> labels = [\n ... f\"{classes[class_id]} {confidence:0.2f}\"\n ... for _, _, confidence, class_id, _\n ... in detections\n ... ]\n >>> annotated_frame = box_annotator.annotate(\n ... scene=image.copy(),\n ... detections=detections,\n ... labels=labels\n ... )\n ```\n \"\"\"\n font = cv2.FONT_HERSHEY_SIMPLEX\n for i in range(len(detections)):\n x1, y1, x2, y2 = detections.xyxy[i].astype(int)\n class_id = (\n detections.class_id[i] if detections.class_id is not None else None\n )\n idx = class_id if class_id is not None else i\n color = (\n self.color.by_idx(idx)\n if isinstance(self.color, ColorPalette)\n else self.color\n )\n cv2.rectangle(\n img=scene,\n pt1=(x1, y1),\n pt2=(x2, y2),\n color=color.as_bgr(),\n thickness=self.thickness,\n )\n if skip_label:\n continue\n\n text = (\n f\"{class_id}\"\n if (labels is None or len(detections) != len(labels))\n else labels[i]\n )\n\n text_width, text_height = cv2.getTextSize(\n text=text,\n fontFace=font,\n fontScale=self.text_scale,\n thickness=self.text_thickness,\n )[0]\n\n text_x = x1 + self.text_padding\n text_y = y1 - self.text_padding\n\n text_background_x1 = x1\n text_background_y1 = y1 - 2 * self.text_padding - text_height\n\n text_background_x2 = x1 + 2 * self.text_padding + text_width\n text_background_y2 = y1\n\n cv2.rectangle(\n img=scene,\n pt1=(text_background_x1, text_background_y1),\n pt2=(text_background_x2, text_background_y2),\n color=color.as_bgr(),\n thickness=cv2.FILLED,\n )\n cv2.putText(\n img=scene,\n text=text,\n org=(text_x, text_y),\n fontFace=font,\n fontScale=self.text_scale,\n color=self.text_color.as_rgb(),\n thickness=self.text_thickness,\n lineType=cv2.LINE_AA,\n )\n return scene\n
A class for overlaying masks on an image using detections provided.
Attributes:
Name Type Description colorUnion[Color, ColorPalette]
The color to fill the mask, can be a single color or a color palette
Source code in supervision/detection/annotate.py
class MaskAnnotator:\n\"\"\"\n A class for overlaying masks on an image using detections provided.\n\n Attributes:\n color (Union[Color, ColorPalette]): The color to fill the mask, can be a single color or a color palette\n \"\"\"\n\n def __init__(\n self,\n color: Union[Color, ColorPalette] = ColorPalette.default(),\n ):\n self.color: Union[Color, ColorPalette] = color\n\n def annotate(\n self, scene: np.ndarray, detections: Detections, opacity: float = 0.5\n ) -> np.ndarray:\n\"\"\"\n Overlays the masks on the given image based on the provided detections, with a specified opacity.\n\n Args:\n scene (np.ndarray): The image on which the masks will be overlaid\n detections (Detections): The detections for which the masks will be overlaid\n opacity (float): The opacity of the masks, between 0 and 1, default is 0.5\n\n Returns:\n np.ndarray: The image with the masks overlaid\n \"\"\"\n if detections.mask is None:\n return scene\n\n for i in np.flip(np.argsort(detections.area)):\n class_id = (\n detections.class_id[i] if detections.class_id is not None else None\n )\n idx = class_id if class_id is not None else i\n color = (\n self.color.by_idx(idx)\n if isinstance(self.color, ColorPalette)\n else self.color\n )\n\n mask = detections.mask[i]\n colored_mask = np.zeros_like(scene, dtype=np.uint8)\n colored_mask[:] = color.as_bgr()\n\n scene = np.where(\n np.expand_dims(mask, axis=-1),\n np.uint8(opacity * colored_mask + (1 - opacity) * scene),\n scene,\n )\n\n return scene\n
Overlays the masks on the given image based on the provided detections, with a specified opacity.
Parameters:
Name Type Description Default scenenp.ndarray
The image on which the masks will be overlaid
required detectionsDetections
The detections for which the masks will be overlaid
required opacityfloat
The opacity of the masks, between 0 and 1, default is 0.5
0.5
Returns:
Type Description np.ndarray
np.ndarray: The image with the masks overlaid
Source code in supervision/detection/annotate.py
def annotate(\n self, scene: np.ndarray, detections: Detections, opacity: float = 0.5\n) -> np.ndarray:\n\"\"\"\n Overlays the masks on the given image based on the provided detections, with a specified opacity.\n\n Args:\n scene (np.ndarray): The image on which the masks will be overlaid\n detections (Detections): The detections for which the masks will be overlaid\n opacity (float): The opacity of the masks, between 0 and 1, default is 0.5\n\n Returns:\n np.ndarray: The image with the masks overlaid\n \"\"\"\n if detections.mask is None:\n return scene\n\n for i in np.flip(np.argsort(detections.area)):\n class_id = (\n detections.class_id[i] if detections.class_id is not None else None\n )\n idx = class_id if class_id is not None else i\n color = (\n self.color.by_idx(idx)\n if isinstance(self.color, ColorPalette)\n else self.color\n )\n\n mask = detections.mask[i]\n colored_mask = np.zeros_like(scene, dtype=np.uint8)\n colored_mask[:] = color.as_bgr()\n\n scene = np.where(\n np.expand_dims(mask, axis=-1),\n np.uint8(opacity * colored_mask + (1 - opacity) * scene),\n scene,\n )\n\n return scene\n
Data class containing information about the detections in a video frame.
Attributes:
Name Type Description xyxynp.ndarray
An array of shape (n, 4) containing the bounding boxes coordinates in format [x1, y1, x2, y2]
masknp.Optional[np.ndarray]
(Optional[np.ndarray]): An array of shape (n, W, H) containing the segmentation masks.
confidenceOptional[np.ndarray]
An array of shape (n,) containing the confidence scores of the detections.
class_idOptional[np.ndarray]
An array of shape (n,) containing the class ids of the detections.
tracker_idOptional[np.ndarray]
An array of shape (n,) containing the tracker ids of the detections.
Source code in supervision/detection/core.py
@dataclass\nclass Detections:\n\"\"\"\n Data class containing information about the detections in a video frame.\n Attributes:\n xyxy (np.ndarray): An array of shape `(n, 4)` containing the bounding boxes coordinates in format `[x1, y1, x2, y2]`\n mask: (Optional[np.ndarray]): An array of shape `(n, W, H)` containing the segmentation masks.\n confidence (Optional[np.ndarray]): An array of shape `(n,)` containing the confidence scores of the detections.\n class_id (Optional[np.ndarray]): An array of shape `(n,)` containing the class ids of the detections.\n tracker_id (Optional[np.ndarray]): An array of shape `(n,)` containing the tracker ids of the detections.\n \"\"\"\n\n xyxy: np.ndarray\n mask: np.Optional[np.ndarray] = None\n confidence: Optional[np.ndarray] = None\n class_id: Optional[np.ndarray] = None\n tracker_id: Optional[np.ndarray] = None\n\n def __post_init__(self):\n n = len(self.xyxy)\n _validate_xyxy(xyxy=self.xyxy, n=n)\n _validate_mask(mask=self.mask, n=n)\n _validate_class_id(class_id=self.class_id, n=n)\n _validate_confidence(confidence=self.confidence, n=n)\n _validate_tracker_id(tracker_id=self.tracker_id, n=n)\n\n def __len__(self):\n\"\"\"\n Returns the number of detections in the Detections object.\n \"\"\"\n return len(self.xyxy)\n\n def __iter__(\n self,\n ) -> Iterator[\n Tuple[\n np.ndarray,\n Optional[np.ndarray],\n Optional[float],\n Optional[int],\n Optional[int],\n ]\n ]:\n\"\"\"\n Iterates over the Detections object and yield a tuple of `(xyxy, mask, confidence, class_id, tracker_id)` for each detection.\n \"\"\"\n for i in range(len(self.xyxy)):\n yield (\n self.xyxy[i],\n self.mask[i] if self.mask is not None else None,\n self.confidence[i] if self.confidence is not None else None,\n self.class_id[i] if self.class_id is not None else None,\n self.tracker_id[i] if self.tracker_id is not None else None,\n )\n\n def __eq__(self, other: Detections):\n return all(\n [\n np.array_equal(self.xyxy, other.xyxy),\n any(\n [\n self.mask is None and other.mask is None,\n np.array_equal(self.mask, other.mask),\n ]\n ),\n any(\n [\n self.class_id is None and other.class_id is None,\n np.array_equal(self.class_id, other.class_id),\n ]\n ),\n any(\n [\n self.confidence is None and other.confidence is None,\n np.array_equal(self.confidence, other.confidence),\n ]\n ),\n any(\n [\n self.tracker_id is None and other.tracker_id is None,\n np.array_equal(self.tracker_id, other.tracker_id),\n ]\n ),\n ]\n )\n\n @classmethod\n def from_yolov5(cls, yolov5_results) -> Detections:\n\"\"\"\n Creates a Detections instance from a [YOLOv5](https://github.com/ultralytics/yolov5) inference result.\n\n Args:\n yolov5_results (yolov5.models.common.Detections): The output Detections instance from YOLOv5\n\n Returns:\n Detections: A new Detections object.\n\n Example:\n ```python\n >>> import cv2\n >>> import torch\n >>> import supervision as sv\n\n >>> image = cv2.imread(SOURCE_IMAGE_PATH)\n >>> model = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n >>> result = model(image)\n >>> detections = sv.Detections.from_yolov5(result)\n ```\n \"\"\"\n yolov5_detections_predictions = yolov5_results.pred[0].cpu().cpu().numpy()\n return cls(\n xyxy=yolov5_detections_predictions[:, :4],\n confidence=yolov5_detections_predictions[:, 4],\n class_id=yolov5_detections_predictions[:, 5].astype(int),\n )\n\n @classmethod\n def from_yolov8(cls, yolov8_results) -> Detections:\n\"\"\"\n Creates a Detections instance from a [YOLOv8](https://github.com/ultralytics/ultralytics) inference result.\n\n Args:\n yolov8_results (ultralytics.yolo.engine.results.Results): The output Results instance from YOLOv8\n\n Returns:\n Detections: A new Detections object.\n\n Example:\n ```python\n >>> import cv2\n >>> from ultralytics import YOLO\n >>> import supervision as sv\n\n >>> image = cv2.imread(SOURCE_IMAGE_PATH)\n >>> model = YOLO('yolov8s.pt')\n >>> result = model(image)[0]\n >>> detections = sv.Detections.from_yolov8(result)\n ```\n \"\"\"\n return cls(\n xyxy=yolov8_results.boxes.xyxy.cpu().numpy(),\n confidence=yolov8_results.boxes.conf.cpu().numpy(),\n class_id=yolov8_results.boxes.cls.cpu().numpy().astype(int),\n mask=extract_yolov8_masks(yolov8_results),\n )\n\n @classmethod\n def from_yolo_nas(cls, yolo_nas_results) -> Detections:\n\"\"\"\n Creates a Detections instance from a [YOLO-NAS](https://github.com/Deci-AI/super-gradients/blob/master/YOLONAS.md) inference result.\n\n Args:\n yolo_nas_results (super_gradients.training.models.prediction_results.ImageDetectionPrediction): The output Results instance from YOLO-NAS\n\n Returns:\n Detections: A new Detections object.\n\n Example:\n ```python\n >>> import cv2\n >>> from super_gradients.training import models\n >>> import supervision as sv\n\n >>> image = cv2.imread(SOURCE_IMAGE_PATH)\n >>> model = models.get('yolo_nas_l', pretrained_weights=\"coco\")\n >>> result = list(model.predict(image, conf=0.35))[0]\n >>> detections = sv.Detections.from_yolo_nas(result)\n ```\n \"\"\"\n return cls(\n xyxy=yolo_nas_results.prediction.bboxes_xyxy,\n confidence=yolo_nas_results.prediction.confidence,\n class_id=yolo_nas_results.prediction.labels.astype(int),\n )\n\n @classmethod\n def from_transformers(cls, transformers_results: dict) -> Detections:\n\"\"\"\n Creates a Detections instance from object detection [transformer](https://github.com/huggingface/transformers) inference result.\n\n Returns:\n Detections: A new Detections object.\n \"\"\"\n return cls(\n xyxy=transformers_results[\"boxes\"].cpu().numpy(),\n confidence=transformers_results[\"scores\"].cpu().numpy(),\n class_id=transformers_results[\"labels\"].cpu().numpy().astype(int),\n )\n\n @classmethod\n def from_detectron2(cls, detectron2_results) -> Detections:\n\"\"\"\n Create a Detections object from the [Detectron2](https://github.com/facebookresearch/detectron2) inference result.\n\n Args:\n detectron2_results: The output of a Detectron2 model containing instances with prediction data.\n\n Returns:\n (Detections): A Detections object containing the bounding boxes, class IDs, and confidences of the predictions.\n\n Example:\n ```python\n >>> import cv2\n >>> from detectron2.engine import DefaultPredictor\n >>> from detectron2.config import get_cfg\n >>> import supervision as sv\n\n >>> image = cv2.imread(SOURCE_IMAGE_PATH)\n >>> cfg = get_cfg()\n >>> cfg.merge_from_file(\"path/to/config.yaml\")\n >>> cfg.MODEL.WEIGHTS = \"path/to/model_weights.pth\"\n >>> predictor = DefaultPredictor(cfg)\n >>> result = predictor(image)\n\n >>> detections = sv.Detections.from_detectron2(result)\n ```\n \"\"\"\n return cls(\n xyxy=detectron2_results[\"instances\"].pred_boxes.tensor.cpu().numpy(),\n confidence=detectron2_results[\"instances\"].scores.cpu().numpy(),\n class_id=detectron2_results[\"instances\"]\n .pred_classes.cpu()\n .numpy()\n .astype(int),\n )\n\n @classmethod\n def from_roboflow(cls, roboflow_result: dict, class_list: List[str]) -> Detections:\n\"\"\"\n Create a Detections object from the [Roboflow](https://roboflow.com/) API inference result.\n\n Args:\n roboflow_result (dict): The result from the Roboflow API containing predictions.\n class_list (List[str]): A list of class names corresponding to the class IDs in the API result.\n\n Returns:\n (Detections): A Detections object containing the bounding boxes, class IDs, and confidences of the predictions.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> roboflow_result = {\n ... \"predictions\": [\n ... {\n ... \"x\": 0.5,\n ... \"y\": 0.5,\n ... \"width\": 0.2,\n ... \"height\": 0.3,\n ... \"class\": \"person\",\n ... \"confidence\": 0.9\n ... },\n ... # ... more predictions ...\n ... ]\n ... }\n >>> class_list = [\"person\", \"car\", \"dog\"]\n\n >>> detections = sv.Detections.from_roboflow(roboflow_result, class_list)\n ```\n \"\"\"\n xyxy, confidence, class_id, masks = process_roboflow_result(\n roboflow_result=roboflow_result, class_list=class_list\n )\n return Detections(\n xyxy=xyxy,\n confidence=confidence,\n class_id=class_id,\n mask=masks,\n )\n\n @classmethod\n def from_sam(cls, sam_result: List[dict]) -> Detections:\n\"\"\"\n Creates a Detections instance from [Segment Anything Model](https://github.com/facebookresearch/segment-anything) inference result.\n\n Args:\n sam_result (List[dict]): The output Results instance from SAM\n\n Returns:\n Detections: A new Detections object.\n\n Example:\n ```python\n >>> import supervision as sv\n >>> from segment_anything import sam_model_registry, SamAutomaticMaskGenerator\n\n >>> sam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)\n >>> mask_generator = SamAutomaticMaskGenerator(sam)\n >>> sam_result = mask_generator.generate(IMAGE)\n >>> detections = sv.Detections.from_sam(sam_result=sam_result)\n ```\n \"\"\"\n sorted_generated_masks = sorted(\n sam_result, key=lambda x: x[\"area\"], reverse=True\n )\n\n xywh = np.array([mask[\"bbox\"] for mask in sorted_generated_masks])\n mask = np.array([mask[\"segmentation\"] for mask in sorted_generated_masks])\n\n return Detections(xyxy=xywh_to_xyxy(boxes_xywh=xywh), mask=mask)\n\n @classmethod\n def empty(cls) -> Detections:\n\"\"\"\n Create an empty Detections object with no bounding boxes, confidences, or class IDs.\n\n Returns:\n (Detections): An empty Detections object.\n\n Example:\n ```python\n >>> from supervision import Detections\n\n >>> empty_detections = Detections.empty()\n ```\n \"\"\"\n return cls(\n xyxy=np.empty((0, 4), dtype=np.float32),\n confidence=np.array([], dtype=np.float32),\n class_id=np.array([], dtype=int),\n )\n\n @classmethod\n def merge(cls, detections_list: List[Detections]) -> Detections:\n\"\"\"\n Merge a list of Detections objects into a single Detections object.\n\n This method takes a list of Detections objects and combines their respective fields (`xyxy`, `mask`,\n `confidence`, `class_id`, and `tracker_id`) into a single Detections object. If all elements in a field are not\n `None`, the corresponding field will be stacked. Otherwise, the field will be set to `None`.\n\n Args:\n detections_list (List[Detections]): A list of Detections objects to merge.\n\n Returns:\n (Detections): A single Detections object containing the merged data from the input list.\n\n Example:\n ```python\n >>> from supervision import Detections\n\n >>> detections_1 = Detections(...)\n >>> detections_2 = Detections(...)\n\n >>> merged_detections = Detections.merge([detections_1, detections_2])\n ```\n \"\"\"\n if len(detections_list) == 0:\n return Detections.empty()\n\n detections_tuples_list = [astuple(detection) for detection in detections_list]\n xyxy, mask, confidence, class_id, tracker_id = [\n list(field) for field in zip(*detections_tuples_list)\n ]\n\n all_not_none = lambda l: all(x is not None for x in l)\n\n xyxy = np.vstack(xyxy)\n mask = np.vstack(mask) if all_not_none(mask) else None\n confidence = np.hstack(confidence) if all_not_none(confidence) else None\n class_id = np.hstack(class_id) if all_not_none(class_id) else None\n tracker_id = np.hstack(tracker_id) if all_not_none(tracker_id) else None\n\n return cls(\n xyxy=xyxy,\n mask=mask,\n confidence=confidence,\n class_id=class_id,\n tracker_id=tracker_id,\n )\n\n def get_anchor_coordinates(self, anchor: Position) -> np.ndarray:\n\"\"\"\n Returns the bounding box coordinates for a specific anchor.\n\n Args:\n anchor (Position): Position of bounding box anchor for which to return the coordinates.\n\n Returns:\n np.ndarray: An array of shape `(n, 2)` containing the bounding box anchor coordinates in format `[x, y]`.\n \"\"\"\n if anchor == Position.CENTER:\n return np.array(\n [\n (self.xyxy[:, 0] + self.xyxy[:, 2]) / 2,\n (self.xyxy[:, 1] + self.xyxy[:, 3]) / 2,\n ]\n ).transpose()\n elif anchor == Position.BOTTOM_CENTER:\n return np.array(\n [(self.xyxy[:, 0] + self.xyxy[:, 2]) / 2, self.xyxy[:, 3]]\n ).transpose()\n\n raise ValueError(f\"{anchor} is not supported.\")\n\n def __getitem__(\n self, index: Union[int, slice, List[int], np.ndarray]\n ) -> Detections:\n\"\"\"\n Get a subset of the Detections object.\n\n Args:\n index (Union[int, slice, List[int], np.ndarray]): The index or indices of the subset of the Detections\n\n Returns:\n (Detections): A subset of the Detections object.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> detections = sv.Detections(...)\n\n >>> first_detection = detections[0]\n\n >>> first_10_detections = detections[0:10]\n\n >>> some_detections = detections[[0, 2, 4]]\n\n >>> class_0_detections = detections[detections.class_id == 0]\n\n >>> high_confidence_detections = detections[detections.confidence > 0.5]\n ```\n \"\"\"\n if isinstance(index, int):\n index = [index]\n return Detections(\n xyxy=self.xyxy[index],\n mask=self.mask[index] if self.mask is not None else None,\n confidence=self.confidence[index] if self.confidence is not None else None,\n class_id=self.class_id[index] if self.class_id is not None else None,\n tracker_id=self.tracker_id[index] if self.tracker_id is not None else None,\n )\n\n @property\n def area(self) -> np.ndarray:\n\"\"\"\n Calculate the area of each detection in the set of object detections. If masks field is defined property\n returns are of each mask. If only box is given property return area of each box.\n\n Returns:\n np.ndarray: An array of floats containing the area of each detection in the format of `(area_1, area_2, ..., area_n)`, where n is the number of detections.\n \"\"\"\n if self.mask is not None:\n return np.array([np.sum(mask) for mask in self.mask])\n else:\n return self.box_area\n\n @property\n def box_area(self) -> np.ndarray:\n\"\"\"\n Calculate the area of each bounding box in the set of object detections.\n\n Returns:\n np.ndarray: An array of floats containing the area of each bounding box in the format of `(area_1, area_2, ..., area_n)`, where n is the number of detections.\n \"\"\"\n return (self.xyxy[:, 3] - self.xyxy[:, 1]) * (self.xyxy[:, 2] - self.xyxy[:, 0])\n\n def with_nms(\n self, threshold: float = 0.5, class_agnostic: bool = False\n ) -> Detections:\n\"\"\"\n Perform non-maximum suppression on the current set of object detections.\n\n Args:\n threshold (float, optional): The intersection-over-union threshold to use for non-maximum suppression. Defaults to 0.5.\n class_agnostic (bool, optional): Whether to perform class-agnostic non-maximum suppression. If True, the class_id of each detection will be ignored. Defaults to False.\n\n Returns:\n Detections: A new Detections object containing the subset of detections after non-maximum suppression.\n\n Raises:\n AssertionError: If `confidence` is None and class_agnostic is False. If `class_id` is None and class_agnostic is False.\n \"\"\"\n if len(self) == 0:\n return self\n\n assert (\n self.confidence is not None\n ), f\"Detections confidence must be given for NMS to be executed.\"\n\n if class_agnostic:\n predictions = np.hstack((self.xyxy, self.confidence.reshape(-1, 1)))\n indices = non_max_suppression(\n predictions=predictions, iou_threshold=threshold\n )\n return self[indices]\n\n assert self.class_id is not None, (\n f\"Detections class_id must be given for NMS to be executed. If you intended to perform class agnostic \"\n f\"NMS set class_agnostic=True.\"\n )\n\n predictions = np.hstack(\n (self.xyxy, self.confidence.reshape(-1, 1), self.class_id.reshape(-1, 1))\n )\n indices = non_max_suppression(predictions=predictions, iou_threshold=threshold)\n return self[indices]\n
Calculate the area of each detection in the set of object detections. If masks field is defined property returns are of each mask. If only box is given property return area of each box.
Returns:
Type Description np.ndarray
np.ndarray: An array of floats containing the area of each detection in the format of (area_1, area_2, ..., area_n), where n is the number of detections.
Calculate the area of each bounding box in the set of object detections.
Returns:
Type Description np.ndarray
np.ndarray: An array of floats containing the area of each bounding box in the format of (area_1, area_2, ..., area_n), where n is the number of detections.
def __getitem__(\n self, index: Union[int, slice, List[int], np.ndarray]\n) -> Detections:\n\"\"\"\n Get a subset of the Detections object.\n\n Args:\n index (Union[int, slice, List[int], np.ndarray]): The index or indices of the subset of the Detections\n\n Returns:\n (Detections): A subset of the Detections object.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> detections = sv.Detections(...)\n\n >>> first_detection = detections[0]\n\n >>> first_10_detections = detections[0:10]\n\n >>> some_detections = detections[[0, 2, 4]]\n\n >>> class_0_detections = detections[detections.class_id == 0]\n\n >>> high_confidence_detections = detections[detections.confidence > 0.5]\n ```\n \"\"\"\n if isinstance(index, int):\n index = [index]\n return Detections(\n xyxy=self.xyxy[index],\n mask=self.mask[index] if self.mask is not None else None,\n confidence=self.confidence[index] if self.confidence is not None else None,\n class_id=self.class_id[index] if self.class_id is not None else None,\n tracker_id=self.tracker_id[index] if self.tracker_id is not None else None,\n )\n
Iterates over the Detections object and yield a tuple of (xyxy, mask, confidence, class_id, tracker_id) for each detection.
Source code in supervision/detection/core.py
def __iter__(\n self,\n) -> Iterator[\n Tuple[\n np.ndarray,\n Optional[np.ndarray],\n Optional[float],\n Optional[int],\n Optional[int],\n ]\n]:\n\"\"\"\n Iterates over the Detections object and yield a tuple of `(xyxy, mask, confidence, class_id, tracker_id)` for each detection.\n \"\"\"\n for i in range(len(self.xyxy)):\n yield (\n self.xyxy[i],\n self.mask[i] if self.mask is not None else None,\n self.confidence[i] if self.confidence is not None else None,\n self.class_id[i] if self.class_id is not None else None,\n self.tracker_id[i] if self.tracker_id is not None else None,\n )\n
Merge a list of Detections objects into a single Detections object.
This method takes a list of Detections objects and combines their respective fields (xyxy, mask, confidence, class_id, and tracker_id) into a single Detections object. If all elements in a field are not None, the corresponding field will be stacked. Otherwise, the field will be set to None.
Parameters:
Name Type Description Default detections_listList[Detections]
A list of Detections objects to merge.
required
Returns:
Type Description Detections
A single Detections object containing the merged data from the input list.
@classmethod\ndef merge(cls, detections_list: List[Detections]) -> Detections:\n\"\"\"\n Merge a list of Detections objects into a single Detections object.\n\n This method takes a list of Detections objects and combines their respective fields (`xyxy`, `mask`,\n `confidence`, `class_id`, and `tracker_id`) into a single Detections object. If all elements in a field are not\n `None`, the corresponding field will be stacked. Otherwise, the field will be set to `None`.\n\n Args:\n detections_list (List[Detections]): A list of Detections objects to merge.\n\n Returns:\n (Detections): A single Detections object containing the merged data from the input list.\n\n Example:\n ```python\n >>> from supervision import Detections\n\n >>> detections_1 = Detections(...)\n >>> detections_2 = Detections(...)\n\n >>> merged_detections = Detections.merge([detections_1, detections_2])\n ```\n \"\"\"\n if len(detections_list) == 0:\n return Detections.empty()\n\n detections_tuples_list = [astuple(detection) for detection in detections_list]\n xyxy, mask, confidence, class_id, tracker_id = [\n list(field) for field in zip(*detections_tuples_list)\n ]\n\n all_not_none = lambda l: all(x is not None for x in l)\n\n xyxy = np.vstack(xyxy)\n mask = np.vstack(mask) if all_not_none(mask) else None\n confidence = np.hstack(confidence) if all_not_none(confidence) else None\n class_id = np.hstack(class_id) if all_not_none(class_id) else None\n tracker_id = np.hstack(tracker_id) if all_not_none(tracker_id) else None\n\n return cls(\n xyxy=xyxy,\n mask=mask,\n confidence=confidence,\n class_id=class_id,\n tracker_id=tracker_id,\n )\n
Perform non-maximum suppression on the current set of object detections.
Parameters:
Name Type Description Default thresholdfloat
The intersection-over-union threshold to use for non-maximum suppression. Defaults to 0.5.
0.5class_agnosticbool
Whether to perform class-agnostic non-maximum suppression. If True, the class_id of each detection will be ignored. Defaults to False.
False
Returns:
Name Type Description DetectionsDetections
A new Detections object containing the subset of detections after non-maximum suppression.
Raises:
Type Description AssertionError
If confidence is None and class_agnostic is False. If class_id is None and class_agnostic is False.
Source code in supervision/detection/core.py
def with_nms(\n self, threshold: float = 0.5, class_agnostic: bool = False\n) -> Detections:\n\"\"\"\n Perform non-maximum suppression on the current set of object detections.\n\n Args:\n threshold (float, optional): The intersection-over-union threshold to use for non-maximum suppression. Defaults to 0.5.\n class_agnostic (bool, optional): Whether to perform class-agnostic non-maximum suppression. If True, the class_id of each detection will be ignored. Defaults to False.\n\n Returns:\n Detections: A new Detections object containing the subset of detections after non-maximum suppression.\n\n Raises:\n AssertionError: If `confidence` is None and class_agnostic is False. If `class_id` is None and class_agnostic is False.\n \"\"\"\n if len(self) == 0:\n return self\n\n assert (\n self.confidence is not None\n ), f\"Detections confidence must be given for NMS to be executed.\"\n\n if class_agnostic:\n predictions = np.hstack((self.xyxy, self.confidence.reshape(-1, 1)))\n indices = non_max_suppression(\n predictions=predictions, iou_threshold=threshold\n )\n return self[indices]\n\n assert self.class_id is not None, (\n f\"Detections class_id must be given for NMS to be executed. If you intended to perform class agnostic \"\n f\"NMS set class_agnostic=True.\"\n )\n\n predictions = np.hstack(\n (self.xyxy, self.confidence.reshape(-1, 1), self.class_id.reshape(-1, 1))\n )\n indices = non_max_suppression(predictions=predictions, iou_threshold=threshold)\n return self[indices]\n
Compute Intersection over Union (IoU) of two sets of bounding boxes - boxes_true and boxes_detection. Both sets of boxes are expected to be in (x_min, y_min, x_max, y_max) format.
Parameters:
Name Type Description Default boxes_truenp.ndarray
2D np.ndarray representing ground-truth boxes. shape = (N, 4) where N is number of true objects.
required boxes_detectionnp.ndarray
2D np.ndarray representing detection boxes. shape = (M, 4) where M is number of detected objects.
required
Returns:
Type Description np.ndarray
np.ndarray: Pairwise IoU of boxes from boxes_true and boxes_detection. shape = (N, M) where N is number of true objects and M is number of detected objects.
Source code in supervision/detection/utils.py
def box_iou_batch(boxes_true: np.ndarray, boxes_detection: np.ndarray) -> np.ndarray:\n\"\"\"\n Compute Intersection over Union (IoU) of two sets of bounding boxes - `boxes_true` and `boxes_detection`. Both sets\n of boxes are expected to be in `(x_min, y_min, x_max, y_max)` format.\n\n Args:\n boxes_true (np.ndarray): 2D `np.ndarray` representing ground-truth boxes. `shape = (N, 4)` where `N` is number of true objects.\n boxes_detection (np.ndarray): 2D `np.ndarray` representing detection boxes. `shape = (M, 4)` where `M` is number of detected objects.\n\n Returns:\n np.ndarray: Pairwise IoU of boxes from `boxes_true` and `boxes_detection`. `shape = (N, M)` where `N` is number of true objects and `M` is number of detected objects.\n \"\"\"\n\n def box_area(box):\n return (box[2] - box[0]) * (box[3] - box[1])\n\n area_true = box_area(boxes_true.T)\n area_detection = box_area(boxes_detection.T)\n\n top_left = np.maximum(boxes_true[:, None, :2], boxes_detection[:, :2])\n bottom_right = np.minimum(boxes_true[:, None, 2:], boxes_detection[:, 2:])\n\n area_inter = np.prod(np.clip(bottom_right - top_left, a_min=0, a_max=None), 2)\n return area_inter / (area_true[:, None] + area_detection - area_inter)\n
Perform Non-Maximum Suppression (NMS) on object detection predictions.
Parameters:
Name Type Description Default predictionsnp.ndarray
An array of object detection predictions in the format of (x_min, y_min, x_max, y_max, score) or (x_min, y_min, x_max, y_max, score, class).
required iou_thresholdfloat
The intersection-over-union threshold to use for non-maximum suppression.
0.5
Returns:
Type Description np.ndarray
np.ndarray: A boolean array indicating which predictions to keep after non-maximum suppression.
Raises:
Type Description AssertionError
If iou_threshold is not within the closed range from 0 to 1.
Source code in supervision/detection/utils.py
def non_max_suppression(\n predictions: np.ndarray, iou_threshold: float = 0.5\n) -> np.ndarray:\n\"\"\"\n Perform Non-Maximum Suppression (NMS) on object detection predictions.\n\n Args:\n predictions (np.ndarray): An array of object detection predictions in the format of `(x_min, y_min, x_max, y_max, score)` or `(x_min, y_min, x_max, y_max, score, class)`.\n iou_threshold (float, optional): The intersection-over-union threshold to use for non-maximum suppression.\n\n Returns:\n np.ndarray: A boolean array indicating which predictions to keep after non-maximum suppression.\n\n Raises:\n AssertionError: If `iou_threshold` is not within the closed range from `0` to `1`.\n \"\"\"\n assert 0 <= iou_threshold <= 1, (\n f\"Value of `iou_threshold` must be in the closed range from 0 to 1, \"\n f\"{iou_threshold} given.\"\n )\n rows, columns = predictions.shape\n\n # add column #5 - category filled with zeros for agnostic nms\n if columns == 5:\n predictions = np.c_[predictions, np.zeros(rows)]\n\n # sort predictions column #4 - score\n sort_index = np.flip(predictions[:, 4].argsort())\n predictions = predictions[sort_index]\n\n boxes = predictions[:, :4]\n categories = predictions[:, 5]\n ious = box_iou_batch(boxes, boxes)\n ious = ious - np.eye(rows)\n\n keep = np.ones(rows, dtype=bool)\n\n for index, (iou, category) in enumerate(zip(ious, categories)):\n if not keep[index]:\n continue\n\n # drop detections with iou > iou_threshold and same category as current detections\n condition = (iou > iou_threshold) & (categories == category)\n keep = keep & ~condition\n\n return keep[sort_index.argsort()]\n
The polygon for which the mask should be generated, given as a list of vertices.
required resolution_whTuple[int, int]
The width and height of the desired resolution.
required
Returns:
Type Description np.ndarray
np.ndarray: The generated 2D mask, where the polygon is marked with 1's and the rest is filled with 0's.
Source code in supervision/detection/utils.py
def polygon_to_mask(polygon: np.ndarray, resolution_wh: Tuple[int, int]) -> np.ndarray:\n\"\"\"Generate a mask from a polygon.\n\n Args:\n polygon (np.ndarray): The polygon for which the mask should be generated, given as a list of vertices.\n resolution_wh (Tuple[int, int]): The width and height of the desired resolution.\n\n Returns:\n np.ndarray: The generated 2D mask, where the polygon is marked with `1`'s and the rest is filled with `0`'s.\n \"\"\"\n width, height = resolution_wh\n mask = np.zeros((height, width), dtype=np.uint8)\n cv2.fillPoly(mask, [polygon], color=1)\n return mask\n
Converts a 3D np.array of 2D bool masks into a 2D np.array of bounding boxes.
Parameters:
Name Type Description Default masksnp.ndarray
A 3D np.array of shape (N, W, H) containing 2D bool masks
required
Returns:
Type Description np.ndarray
np.ndarray: A 2D np.array of shape (N, 4) containing the bounding boxes (x_min, y_min, x_max, y_max) for each mask
Source code in supervision/detection/utils.py
def mask_to_xyxy(masks: np.ndarray) -> np.ndarray:\n\"\"\"\n Converts a 3D `np.array` of 2D bool masks into a 2D `np.array` of bounding boxes.\n\n Parameters:\n masks (np.ndarray): A 3D `np.array` of shape `(N, W, H)` containing 2D bool masks\n\n Returns:\n np.ndarray: A 2D `np.array` of shape `(N, 4)` containing the bounding boxes `(x_min, y_min, x_max, y_max)` for each mask\n \"\"\"\n n = masks.shape[0]\n bboxes = np.zeros((n, 4), dtype=int)\n\n for i, mask in enumerate(masks):\n rows, cols = np.where(mask)\n\n if len(rows) > 0 and len(cols) > 0:\n x_min, x_max = np.min(cols), np.max(cols)\n y_min, y_max = np.min(rows), np.max(rows)\n bboxes[i, :] = [x_min, y_min, x_max, y_max]\n\n return bboxes\n
A binary mask represented as a 2D NumPy array of shape (H, W), where H and W are the height and width of the mask, respectively.
required
Returns:
Type Description List[np.ndarray]
List[np.ndarray]: A list of polygons, where each polygon is represented by a NumPy array of shape (N, 2), containing the x, y coordinates of the points. Polygons with fewer points than MIN_POLYGON_POINT_COUNT = 3 are excluded from the output.
Source code in supervision/detection/utils.py
def mask_to_polygons(mask: np.ndarray) -> List[np.ndarray]:\n\"\"\"\n Converts a binary mask to a list of polygons.\n\n Parameters:\n mask (np.ndarray): A binary mask represented as a 2D NumPy array of shape `(H, W)`,\n where H and W are the height and width of the mask, respectively.\n\n Returns:\n List[np.ndarray]: A list of polygons, where each polygon is represented by a NumPy array of shape `(N, 2)`,\n containing the `x`, `y` coordinates of the points. Polygons with fewer points than `MIN_POLYGON_POINT_COUNT = 3`\n are excluded from the output.\n \"\"\"\n\n contours, _ = cv2.findContours(\n mask.astype(np.uint8), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE\n )\n return [\n np.squeeze(contour, axis=1)\n for contour in contours\n if contour.shape[0] >= MIN_POLYGON_POINT_COUNT\n ]\n
Converts a polygon represented by a NumPy array into a bounding box.
Parameters:
Name Type Description Default polygonnp.ndarray
A polygon represented by a NumPy array of shape (N, 2), containing the x, y coordinates of the points.
required
Returns:
Type Description np.ndarray
np.ndarray: A 1D NumPy array containing the bounding box (x_min, y_min, x_max, y_max) of the input polygon.
Source code in supervision/detection/utils.py
def polygon_to_xyxy(polygon: np.ndarray) -> np.ndarray:\n\"\"\"\n Converts a polygon represented by a NumPy array into a bounding box.\n\n Parameters:\n polygon (np.ndarray): A polygon represented by a NumPy array of shape `(N, 2)`,\n containing the `x`, `y` coordinates of the points.\n\n Returns:\n np.ndarray: A 1D NumPy array containing the bounding box `(x_min, y_min, x_max, y_max)` of the input polygon.\n \"\"\"\n x_min, y_min = np.min(polygon, axis=0)\n x_max, y_max = np.max(polygon, axis=0)\n return np.array([x_min, y_min, x_max, y_max])\n
Name Type Description Default polygonsList[np.ndarray]
A list of polygons, where each polygon is represented by a NumPy array of shape (N, 2), containing the x, y coordinates of the points.
required min_areaOptional[float]
The minimum area threshold. Only polygons with an area greater than or equal to this value will be included in the output. If set to None, no minimum area constraint will be applied.
Nonemax_areaOptional[float]
The maximum area threshold. Only polygons with an area less than or equal to this value will be included in the output. If set to None, no maximum area constraint will be applied.
None
Returns:
Type Description List[np.ndarray]
List[np.ndarray]: A new list of polygons containing only those with areas within the specified thresholds.
Source code in supervision/detection/utils.py
def filter_polygons_by_area(\n polygons: List[np.ndarray],\n min_area: Optional[float] = None,\n max_area: Optional[float] = None,\n) -> List[np.ndarray]:\n\"\"\"\n Filters a list of polygons based on their area.\n\n Parameters:\n polygons (List[np.ndarray]): A list of polygons, where each polygon is represented by a NumPy array of shape `(N, 2)`,\n containing the `x`, `y` coordinates of the points.\n min_area (Optional[float]): The minimum area threshold. Only polygons with an area greater than or equal to this value\n will be included in the output. If set to None, no minimum area constraint will be applied.\n max_area (Optional[float]): The maximum area threshold. Only polygons with an area less than or equal to this value\n will be included in the output. If set to None, no maximum area constraint will be applied.\n\n Returns:\n List[np.ndarray]: A new list of polygons containing only those with areas within the specified thresholds.\n \"\"\"\n if min_area is None and max_area is None:\n return polygons\n ares = [cv2.contourArea(polygon) for polygon in polygons]\n return [\n polygon\n for polygon, area in zip(polygons, ares)\n if (min_area is None or area >= min_area)\n and (max_area is None or area <= max_area)\n ]\n
A class for defining a polygon-shaped zone within a frame for detecting objects.
Attributes:
Name Type Description polygonnp.ndarray
A polygon represented by a numpy array of shape (N, 2), containing the x, y coordinates of the points.
frame_resolution_whTuple[int, int]
The frame resolution (width, height)
triggering_positionPosition
The position within the bounding box that triggers the zone (default: Position.BOTTOM_CENTER)
current_countint
The current count of detected objects within the zone
masknp.ndarray
The 2D bool mask for the polygon zone
Source code in supervision/detection/tools/polygon_zone.py
class PolygonZone:\n\"\"\"\n A class for defining a polygon-shaped zone within a frame for detecting objects.\n\n Attributes:\n polygon (np.ndarray): A polygon represented by a numpy array of shape `(N, 2)`, containing the `x`, `y` coordinates of the points.\n frame_resolution_wh (Tuple[int, int]): The frame resolution (width, height)\n triggering_position (Position): The position within the bounding box that triggers the zone (default: Position.BOTTOM_CENTER)\n current_count (int): The current count of detected objects within the zone\n mask (np.ndarray): The 2D bool mask for the polygon zone\n \"\"\"\n\n def __init__(\n self,\n polygon: np.ndarray,\n frame_resolution_wh: Tuple[int, int],\n triggering_position: Position = Position.BOTTOM_CENTER,\n ):\n self.polygon = polygon.astype(int)\n self.frame_resolution_wh = frame_resolution_wh\n self.triggering_position = triggering_position\n self.current_count = 0\n\n width, height = frame_resolution_wh\n self.mask = polygon_to_mask(\n polygon=polygon, resolution_wh=(width + 1, height + 1)\n )\n\n def trigger(self, detections: Detections) -> np.ndarray:\n\"\"\"\n Determines if the detections are within the polygon zone.\n\n Parameters:\n detections (Detections): The detections to be checked against the polygon zone\n\n Returns:\n np.ndarray: A boolean numpy array indicating if each detection is within the polygon zone\n \"\"\"\n\n clipped_xyxy = clip_boxes(\n boxes_xyxy=detections.xyxy, frame_resolution_wh=self.frame_resolution_wh\n )\n clipped_detections = replace(detections, xyxy=clipped_xyxy)\n clipped_anchors = np.ceil(\n clipped_detections.get_anchor_coordinates(anchor=self.triggering_position)\n ).astype(int)\n is_in_zone = self.mask[clipped_anchors[:, 1], clipped_anchors[:, 0]]\n self.current_count = np.sum(is_in_zone)\n return is_in_zone.astype(bool)\n
Determines if the detections are within the polygon zone.
Parameters:
Name Type Description Default detectionsDetections
The detections to be checked against the polygon zone
required
Returns:
Type Description np.ndarray
np.ndarray: A boolean numpy array indicating if each detection is within the polygon zone
Source code in supervision/detection/tools/polygon_zone.py
def trigger(self, detections: Detections) -> np.ndarray:\n\"\"\"\n Determines if the detections are within the polygon zone.\n\n Parameters:\n detections (Detections): The detections to be checked against the polygon zone\n\n Returns:\n np.ndarray: A boolean numpy array indicating if each detection is within the polygon zone\n \"\"\"\n\n clipped_xyxy = clip_boxes(\n boxes_xyxy=detections.xyxy, frame_resolution_wh=self.frame_resolution_wh\n )\n clipped_detections = replace(detections, xyxy=clipped_xyxy)\n clipped_anchors = np.ceil(\n clipped_detections.get_anchor_coordinates(anchor=self.triggering_position)\n ).astype(int)\n is_in_zone = self.mask[clipped_anchors[:, 1], clipped_anchors[:, 0]]\n self.current_count = np.sum(is_in_zone)\n return is_in_zone.astype(bool)\n
A class for annotating a polygon-shaped zone within a frame with a count of detected objects.
Attributes:
Name Type Description zonePolygonZone
The polygon zone to be annotated
colorColor
The color to draw the polygon lines
thicknessint
The thickness of the polygon lines, default is 2
text_colorColor
The color of the text on the polygon, default is black
text_scalefloat
The scale of the text on the polygon, default is 0.5
text_thicknessint
The thickness of the text on the polygon, default is 1
text_paddingint
The padding around the text on the polygon, default is 10
fontint
The font type for the text on the polygon, default is cv2.FONT_HERSHEY_SIMPLEX
centerTuple[int, int]
The center of the polygon for text placement
Source code in supervision/detection/tools/polygon_zone.py
class PolygonZoneAnnotator:\n\"\"\"\n A class for annotating a polygon-shaped zone within a frame with a count of detected objects.\n\n Attributes:\n zone (PolygonZone): The polygon zone to be annotated\n color (Color): The color to draw the polygon lines\n thickness (int): The thickness of the polygon lines, default is 2\n text_color (Color): The color of the text on the polygon, default is black\n text_scale (float): The scale of the text on the polygon, default is 0.5\n text_thickness (int): The thickness of the text on the polygon, default is 1\n text_padding (int): The padding around the text on the polygon, default is 10\n font (int): The font type for the text on the polygon, default is cv2.FONT_HERSHEY_SIMPLEX\n center (Tuple[int, int]): The center of the polygon for text placement\n \"\"\"\n\n def __init__(\n self,\n zone: PolygonZone,\n color: Color,\n thickness: int = 2,\n text_color: Color = Color.black(),\n text_scale: float = 0.5,\n text_thickness: int = 1,\n text_padding: int = 10,\n ):\n self.zone = zone\n self.color = color\n self.thickness = thickness\n self.text_color = text_color\n self.text_scale = text_scale\n self.text_thickness = text_thickness\n self.text_padding = text_padding\n self.font = cv2.FONT_HERSHEY_SIMPLEX\n self.center = get_polygon_center(polygon=zone.polygon)\n\n def annotate(self, scene: np.ndarray, label: Optional[str] = None) -> np.ndarray:\n\"\"\"\n Annotates the polygon zone within a frame with a count of detected objects.\n\n Parameters:\n scene (np.ndarray): The image on which the polygon zone will be annotated\n label (Optional[str]): An optional label for the count of detected objects within the polygon zone (default: None)\n\n Returns:\n np.ndarray: The image with the polygon zone and count of detected objects\n \"\"\"\n annotated_frame = draw_polygon(\n scene=scene,\n polygon=self.zone.polygon,\n color=self.color,\n thickness=self.thickness,\n )\n\n annotated_frame = draw_text(\n scene=annotated_frame,\n text=str(self.zone.current_count) if label is None else label,\n text_anchor=self.center,\n background_color=self.color,\n text_color=self.text_color,\n text_scale=self.text_scale,\n text_thickness=self.text_thickness,\n text_padding=self.text_padding,\n text_font=self.font,\n )\n\n return annotated_frame\n
Annotates the polygon zone within a frame with a count of detected objects.
Parameters:
Name Type Description Default scenenp.ndarray
The image on which the polygon zone will be annotated
required labelOptional[str]
An optional label for the count of detected objects within the polygon zone (default: None)
None
Returns:
Type Description np.ndarray
np.ndarray: The image with the polygon zone and count of detected objects
Source code in supervision/detection/tools/polygon_zone.py
def annotate(self, scene: np.ndarray, label: Optional[str] = None) -> np.ndarray:\n\"\"\"\n Annotates the polygon zone within a frame with a count of detected objects.\n\n Parameters:\n scene (np.ndarray): The image on which the polygon zone will be annotated\n label (Optional[str]): An optional label for the count of detected objects within the polygon zone (default: None)\n\n Returns:\n np.ndarray: The image with the polygon zone and count of detected objects\n \"\"\"\n annotated_frame = draw_polygon(\n scene=scene,\n polygon=self.zone.polygon,\n color=self.color,\n thickness=self.thickness,\n )\n\n annotated_frame = draw_text(\n scene=annotated_frame,\n text=str(self.zone.current_count) if label is None else label,\n text_anchor=self.center,\n background_color=self.color,\n text_color=self.text_color,\n text_scale=self.text_scale,\n text_thickness=self.text_thickness,\n text_padding=self.text_padding,\n text_font=self.font,\n )\n\n return annotated_frame\n
def draw_line(\n scene: np.ndarray, start: Point, end: Point, color: Color, thickness: int = 2\n) -> np.ndarray:\n\"\"\"\n Draws a line on a given scene.\n\n Parameters:\n scene (np.ndarray): The scene on which the line will be drawn\n start (Point): The starting point of the line\n end (Point): The end point of the line\n color (Color): The color of the line\n thickness (int): The thickness of the line\n\n Returns:\n np.ndarray: The scene with the line drawn on it\n \"\"\"\n cv2.line(\n scene,\n start.as_xy_int_tuple(),\n end.as_xy_int_tuple(),\n color.as_bgr(),\n thickness=thickness,\n )\n return scene\n
np.ndarray: The scene with the rectangle drawn on it
Source code in supervision/draw/utils.py
def draw_rectangle(\n scene: np.ndarray, rect: Rect, color: Color, thickness: int = 2\n) -> np.ndarray:\n\"\"\"\n Draws a rectangle on an image.\n\n Parameters:\n scene (np.ndarray): The scene on which the rectangle will be drawn\n rect (Rect): The rectangle to be drawn\n color (Color): The color of the rectangle\n thickness (int): The thickness of the rectangle border\n\n Returns:\n np.ndarray: The scene with the rectangle drawn on it\n \"\"\"\n cv2.rectangle(\n scene,\n rect.top_left.as_xy_int_tuple(),\n rect.bottom_right.as_xy_int_tuple(),\n color.as_bgr(),\n thickness=thickness,\n )\n return scene\n
np.ndarray: The scene with the rectangle drawn on it
Source code in supervision/draw/utils.py
def draw_filled_rectangle(scene: np.ndarray, rect: Rect, color: Color) -> np.ndarray:\n\"\"\"\n Draws a filled rectangle on an image.\n\n Parameters:\n scene (np.ndarray): The scene on which the rectangle will be drawn\n rect (Rect): The rectangle to be drawn\n color (Color): The color of the rectangle\n\n Returns:\n np.ndarray: The scene with the rectangle drawn on it\n \"\"\"\n cv2.rectangle(\n scene,\n rect.top_left.as_xy_int_tuple(),\n rect.bottom_right.as_xy_int_tuple(),\n color.as_bgr(),\n -1,\n )\n return scene\n
The polygon to be drawn, given as a list of vertices.
required colorColor
The color of the polygon.
required thicknessint
The thickness of the polygon lines, by default 2.
2
Returns:
Type Description np.ndarray
np.ndarray: The scene with the polygon drawn on it.
Source code in supervision/draw/utils.py
def draw_polygon(\n scene: np.ndarray, polygon: np.ndarray, color: Color, thickness: int = 2\n) -> np.ndarray:\n\"\"\"Draw a polygon on a scene.\n\n Parameters:\n scene (np.ndarray): The scene to draw the polygon on.\n polygon (np.ndarray): The polygon to be drawn, given as a list of vertices.\n color (Color): The color of the polygon.\n thickness (int, optional): The thickness of the polygon lines, by default 2.\n\n Returns:\n np.ndarray: The scene with the polygon drawn on it.\n \"\"\"\n cv2.polylines(\n scene, [polygon], isClosed=True, color=color.as_bgr(), thickness=thickness\n )\n return scene\n
A 2-dimensional numpy ndarray representing an image or scene.
required textstr
The text to be drawn.
required text_anchorPoint
The anchor point for the text, represented as a Point object with x and y attributes.
required text_colorColor
The color of the text. Defaults to black.
Color.black()text_scalefloat
The scale of the text. Defaults to 0.5.
0.5text_thicknessint
The thickness of the text. Defaults to 1.
1text_paddingint
The amount of padding to add around the text when drawing a rectangle in the background. Defaults to 10.
10text_fontint
The font to use for the text. Defaults to cv2.FONT_HERSHEY_SIMPLEX.
cv2.FONT_HERSHEY_SIMPLEXbackground_colorColor
The color of the background rectangle, if one is to be drawn. Defaults to None.
None
Returns:
Type Description np.ndarray
np.ndarray: The input scene with the text drawn on it.
Examples:
>>> scene = np.zeros((100, 100, 3), dtype=np.uint8)\n>>> text_anchor = Point(x=50, y=50)\n>>> scene = draw_text(scene=scene, text=\"Hello, world!\", text_anchor=text_anchor)\n
Source code in supervision/draw/utils.py
def draw_text(\n scene: np.ndarray,\n text: str,\n text_anchor: Point,\n text_color: Color = Color.black(),\n text_scale: float = 0.5,\n text_thickness: int = 1,\n text_padding: int = 10,\n text_font: int = cv2.FONT_HERSHEY_SIMPLEX,\n background_color: Optional[Color] = None,\n) -> np.ndarray:\n\"\"\"\n Draw text with background on a scene.\n\n Parameters:\n scene (np.ndarray): A 2-dimensional numpy ndarray representing an image or scene.\n text (str): The text to be drawn.\n text_anchor (Point): The anchor point for the text, represented as a Point object with x and y attributes.\n text_color (Color, optional): The color of the text. Defaults to black.\n text_scale (float, optional): The scale of the text. Defaults to 0.5.\n text_thickness (int, optional): The thickness of the text. Defaults to 1.\n text_padding (int, optional): The amount of padding to add around the text when drawing a rectangle in the background. Defaults to 10.\n text_font (int, optional): The font to use for the text. Defaults to cv2.FONT_HERSHEY_SIMPLEX.\n background_color (Color, optional): The color of the background rectangle, if one is to be drawn. Defaults to None.\n\n Returns:\n np.ndarray: The input scene with the text drawn on it.\n\n Examples:\n ```python\n >>> scene = np.zeros((100, 100, 3), dtype=np.uint8)\n >>> text_anchor = Point(x=50, y=50)\n >>> scene = draw_text(scene=scene, text=\"Hello, world!\", text_anchor=text_anchor)\n ```\n \"\"\"\n text_width, text_height = cv2.getTextSize(\n text=text,\n fontFace=text_font,\n fontScale=text_scale,\n thickness=text_thickness,\n )[0]\n text_rect = Rect(\n x=text_anchor.x - text_width // 2,\n y=text_anchor.y - text_height // 2,\n width=text_width,\n height=text_height,\n ).pad(text_padding)\n\n if background_color is not None:\n scene = draw_filled_rectangle(\n scene=scene, rect=text_rect, color=background_color\n )\n\n cv2.putText(\n img=scene,\n text=text,\n org=(text_anchor.x - text_width // 2, text_anchor.y + text_height // 2),\n fontFace=text_font,\n fontScale=text_scale,\n color=text_color.as_bgr(),\n thickness=text_thickness,\n lineType=cv2.LINE_AA,\n )\n return scene\n
The advanced filtering capabilities of the Detections class offer users a versatile and efficient way to narrow down and refine object detections. This section outlines various filtering methods, including filtering by specific class or a set of classes, confidence, object area, bounding box area, relative area, box dimensions, and designated zones. Each method is demonstrated with concise code examples to provide users with a clear understanding of how to implement the filters in their applications.
"},{"location":"quickstart/detections/#by-specific-class","title":"by specific class","text":"
Allows you to select detections that belong only to one selected class.
AfterBefore
import supervision as sv\n\ndetections = sv.Detections(...)\ndetections = detections[detections.class_id == 0]\n
import supervision as sv\n\ndetections = sv.Detections(...)\ndetections = detections[detections.class_id == 0]\n
"},{"location":"quickstart/detections/#by-set-of-classes","title":"by set of classes","text":"
Allows you to select detections that belong only to selected set of classes.
AfterBefore
import numpy as np\nimport supervision as sv\n\nselected_classes = [0, 2, 3]\ndetections = sv.Detections(...)\ndetections = detections[np.isin(detections.class_id, selected_classes)]\n
import numpy as np\nimport supervision as sv\n\nclass_id = [0, 2, 3]\ndetections = sv.Detections(...)\ndetections = detections[np.isin(detections.class_id, class_id)]\n
Allows you to select detections based on their size. We define the area as the number of pixels occupied by the detection in the image. In the example below, we have sifted out the detections that are too small.
AfterBefore
import supervision as sv\n\ndetections = sv.Detections(...)\ndetections = detections[detections.area > 1000]\n
import supervision as sv\n\ndetections = sv.Detections(...)\ndetections = detections[detections.area > 1000]\n
Allows you to select detections based on their size in relation to the size of whole image. Sometimes the concept of detection size changes depending on the image. Detection occupying 10000 square px can be large on a 1280x720 image but small on a 3840x2160 image. In such cases, we can filter out detections based on the percentage of the image area occupied by them. In the example below, we remove too large detections.
Allows you to select detections based on their dimensions. The size of the bounding box, as well as its coordinates, can be criteria for rejecting detection. Implementing such filtering requires a bit of custom code but is relatively simple and fast.
Allows you to use Detections in combination with PolygonZone to weed out bounding boxes that are in and out of the zone. In the example below you can see how to filter out all detections located in the lower part of the image.
Detections' greatest strength, however, is that you can build arbitrarily complex logical conditions by simply combining separate conditions using & or |.
List files in a directory with specified extensions or all files if no extensions are provided.
Parameters:
Name Type Description Default directoryUnion[str, Path]
The directory path as a string or Path object.
required extensionsOptional[List[str]]
A list of file extensions to filter. Default is None, which lists all files.
None
Returns:
Type Description List[Path]
A list of Path objects for the matching files.
Examples:
>>> import supervision as sv\n\n>>> # List all files in the directory\n>>> files = sv.list_files_with_extensions(directory='my_directory')\n\n>>> # List only files with '.txt' and '.md' extensions\n>>> files = sv.list_files_with_extensions(directory='my_directory', extensions=['txt', 'md'])\n
Source code in supervision/utils/file.py
def list_files_with_extensions(\n directory: Union[str, Path], extensions: Optional[List[str]] = None\n) -> List[Path]:\n\"\"\"\n List files in a directory with specified extensions or all files if no extensions are provided.\n\n Args:\n directory (Union[str, Path]): The directory path as a string or Path object.\n extensions (Optional[List[str]]): A list of file extensions to filter. Default is None, which lists all files.\n\n Returns:\n (List[Path]): A list of Path objects for the matching files.\n\n Examples:\n ```python\n >>> import supervision as sv\n\n >>> # List all files in the directory\n >>> files = sv.list_files_with_extensions(directory='my_directory')\n\n >>> # List only files with '.txt' and '.md' extensions\n >>> files = sv.list_files_with_extensions(directory='my_directory', extensions=['txt', 'md'])\n ```\n \"\"\"\n directory = Path(directory)\n files_with_extensions = []\n\n if extensions is not None:\n for ext in extensions:\n files_with_extensions.extend(directory.glob(f\"*.{ext}\"))\n else:\n files_with_extensions.extend(directory.glob(\"*\"))\n\n return files_with_extensions\n
"},{"location":"utils/image/","title":"Image","text":""},{"location":"utils/image/#imagesink","title":"ImageSink","text":"Source code in supervision/utils/image.py
class ImageSink:\n def __init__(\n self,\n target_dir_path: str,\n overwrite: bool = False,\n image_name_pattern: str = \"image_{:05d}.png\",\n ):\n\"\"\"\n Initialize a context manager for saving images.\n\n Args:\n target_dir_path (str): The target directory where images will be saved.\n overwrite (bool, optional): Whether to overwrite the existing directory. Defaults to False.\n image_name_pattern (str, optional): The image file name pattern. Defaults to \"image_{:05d}.png\".\n\n Examples:\n ```python\n >>> import supervision as sv\n\n >>> with sv.ImageSink(target_dir_path='target/directory/path', overwrite=True) as sink:\n ... for image in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):\n ... sink.save_image(image=image)\n ```\n \"\"\"\n self.target_dir_path = target_dir_path\n self.overwrite = overwrite\n self.image_name_pattern = image_name_pattern\n self.image_count = 0\n\n def __enter__(self):\n if os.path.exists(self.target_dir_path):\n if self.overwrite:\n shutil.rmtree(self.target_dir_path)\n os.makedirs(self.target_dir_path)\n else:\n os.makedirs(self.target_dir_path)\n\n return self\n\n def save_image(self, image: np.ndarray, image_name: Optional[str] = None):\n\"\"\"\n Save a given image in the target directory.\n\n Args:\n image (np.ndarray): The image to be saved.\n image_name (str, optional): The name to use for the saved image. If not provided, a name will be generated using the `image_name_pattern`.\n \"\"\"\n if image_name is None:\n image_name = self.image_name_pattern.format(self.image_count)\n\n image_path = os.path.join(self.target_dir_path, image_name)\n cv2.imwrite(image_path, image)\n self.image_count += 1\n\n def __exit__(self, exc_type, exc_value, exc_traceback):\n pass\n
Whether to overwrite the existing directory. Defaults to False.
Falseimage_name_patternstr
The image file name pattern. Defaults to \"image_{:05d}.png\".
'image_{:05d}.png'
Examples:
>>> import supervision as sv\n\n>>> with sv.ImageSink(target_dir_path='target/directory/path', overwrite=True) as sink:\n... for image in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):\n... sink.save_image(image=image)\n
Source code in supervision/utils/image.py
def __init__(\n self,\n target_dir_path: str,\n overwrite: bool = False,\n image_name_pattern: str = \"image_{:05d}.png\",\n):\n\"\"\"\n Initialize a context manager for saving images.\n\n Args:\n target_dir_path (str): The target directory where images will be saved.\n overwrite (bool, optional): Whether to overwrite the existing directory. Defaults to False.\n image_name_pattern (str, optional): The image file name pattern. Defaults to \"image_{:05d}.png\".\n\n Examples:\n ```python\n >>> import supervision as sv\n\n >>> with sv.ImageSink(target_dir_path='target/directory/path', overwrite=True) as sink:\n ... for image in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):\n ... sink.save_image(image=image)\n ```\n \"\"\"\n self.target_dir_path = target_dir_path\n self.overwrite = overwrite\n self.image_name_pattern = image_name_pattern\n self.image_count = 0\n
The name to use for the saved image. If not provided, a name will be generated using the image_name_pattern.
None Source code in supervision/utils/image.py
def save_image(self, image: np.ndarray, image_name: Optional[str] = None):\n\"\"\"\n Save a given image in the target directory.\n\n Args:\n image (np.ndarray): The image to be saved.\n image_name (str, optional): The name to use for the saved image. If not provided, a name will be generated using the `image_name_pattern`.\n \"\"\"\n if image_name is None:\n image_name = self.image_name_pattern.format(self.image_count)\n\n image_path = os.path.join(self.target_dir_path, image_name)\n cv2.imwrite(image_path, image)\n self.image_count += 1\n
Crops the given image based on the given bounding box.
Parameters:
Name Type Description Default imagenp.ndarray
The image to be cropped, represented as a numpy array.
required xyxynp.ndarray
A numpy array containing the bounding box coordinates in the format (x1, y1, x2, y2).
required
Returns:
Type Description np.ndarray
The cropped image as a numpy array.
Examples:
>>> import supervision as sv\n\n>>> detection = sv.Detections(...)\n>>> with sv.ImageSink(target_dir_path='target/directory/path') as sink:\n... for xyxy in detection.xyxy:\n... cropped_image = sv.crop(image=image, xyxy=xyxy)\n... sink.save_image(image=image)\n
Source code in supervision/utils/image.py
def crop(image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:\n\"\"\"\n Crops the given image based on the given bounding box.\n\n Args:\n image (np.ndarray): The image to be cropped, represented as a numpy array.\n xyxy (np.ndarray): A numpy array containing the bounding box coordinates in the format (x1, y1, x2, y2).\n\n Returns:\n (np.ndarray): The cropped image as a numpy array.\n\n Examples:\n ```python\n >>> import supervision as sv\n\n >>> detection = sv.Detections(...)\n >>> with sv.ImageSink(target_dir_path='target/directory/path') as sink:\n ... for xyxy in detection.xyxy:\n ... cropped_image = sv.crop(image=image, xyxy=xyxy)\n ... sink.save_image(image=image)\n ```\n \"\"\"\n\n xyxy = np.round(xyxy).astype(int)\n x1, y1, x2, y2 = xyxy\n cropped_img = image[y1:y2, x1:x2]\n return cropped_img\n
def plot_images_grid(\n images: List[np.ndarray],\n grid_size: Tuple[int, int],\n titles: Optional[List[str]] = None,\n size: Tuple[int, int] = (12, 12),\n cmap: Optional[str] = \"gray\",\n) -> None:\n\"\"\"\n Plots images in a grid using matplotlib.\n\n Args:\n images (List[np.ndarray]): A list of images as numpy arrays.\n grid_size (Tuple[int, int]): A tuple specifying the number of rows and columns for the grid.\n titles (Optional[List[str]]): A list of titles for each image. Defaults to None.\n size (Tuple[int, int]): A tuple specifying the width and height of the entire plot in inches.\n cmap (str): the colormap to use for single channel images.\n\n Raises:\n ValueError: If the number of images exceeds the grid size.\n\n Examples:\n ```python\n >>> import cv2\n >>> import supervision as sv\n\n >>> image1 = cv2.imread(\"path/to/image1.jpg\")\n >>> image2 = cv2.imread(\"path/to/image2.jpg\")\n >>> image3 = cv2.imread(\"path/to/image3.jpg\")\n\n >>> images = [image1, image2, image3]\n >>> titles = [\"Image 1\", \"Image 2\", \"Image 3\"]\n\n %matplotlib inline\n >>> plot_images_grid(images, grid_size=(2, 2), titles=titles, size=(16, 16))\n ```\n \"\"\"\n nrows, ncols = grid_size\n\n if len(images) > nrows * ncols:\n raise ValueError(\n \"The number of images exceeds the grid size. Please increase the grid size or reduce the number of images.\"\n )\n\n fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=size)\n\n for idx, ax in enumerate(axes.flat):\n if idx < len(images):\n if images[idx].ndim == 2:\n ax.imshow(images[idx], cmap=cmap)\n else:\n ax.imshow(cv2.cvtColor(images[idx], cv2.COLOR_BGR2RGB))\n\n if titles is not None and idx < len(titles):\n ax.set_title(titles[idx])\n\n ax.axis(\"off\")\n plt.show()\n
@dataclass\nclass VideoInfo:\n\"\"\"\n A class to store video information, including width, height, fps and total number of frames.\n\n Attributes:\n width (int): width of the video in pixels\n height (int): height of the video in pixels\n fps (int): frames per second of the video\n total_frames (int, optional): total number of frames in the video, default is None\n\n Examples:\n ```python\n >>> import supervision as sv\n\n >>> video_info = sv.VideoInfo.from_video_path(video_path='video.mp4')\n\n >>> video_info\n VideoInfo(width=3840, height=2160, fps=25, total_frames=538)\n\n >>> video_info.resolution_wh\n (3840, 2160)\n ```\n \"\"\"\n\n width: int\n height: int\n fps: int\n total_frames: Optional[int] = None\n\n @classmethod\n def from_video_path(cls, video_path: str) -> VideoInfo:\n video = cv2.VideoCapture(video_path)\n if not video.isOpened():\n raise Exception(f\"Could not open video at {video_path}\")\n\n width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))\n height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))\n fps = int(video.get(cv2.CAP_PROP_FPS))\n total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))\n video.release()\n return VideoInfo(width, height, fps, total_frames)\n\n @property\n def resolution_wh(self) -> Tuple[int, int]:\n return self.width, self.height\n
Context manager that saves video frames to a file using OpenCV.
Attributes:
Name Type Description target_pathstr
The path to the output file where the video will be saved.
video_infoVideoInfo
Information about the video resolution, fps, and total frame count.
Example
>>> import supervision as sv\n\n>>> video_info = sv.VideoInfo.from_video_path(video_path='source_video.mp4')\n\n>>> with sv.VideoSink(target_path='target_video.mp4', video_info=video_info) as sink:\n... for frame in get_video_frames_generator(source_path='source_video.mp4', stride=2):\n... sink.write_frame(frame=frame)\n
Source code in supervision/utils/video.py
class VideoSink:\n\"\"\"\n Context manager that saves video frames to a file using OpenCV.\n\n Attributes:\n target_path (str): The path to the output file where the video will be saved.\n video_info (VideoInfo): Information about the video resolution, fps, and total frame count.\n\n Example:\n ```python\n >>> import supervision as sv\n\n >>> video_info = sv.VideoInfo.from_video_path(video_path='source_video.mp4')\n\n >>> with sv.VideoSink(target_path='target_video.mp4', video_info=video_info) as sink:\n ... for frame in get_video_frames_generator(source_path='source_video.mp4', stride=2):\n ... sink.write_frame(frame=frame)\n ```\n \"\"\"\n\n def __init__(self, target_path: str, video_info: VideoInfo):\n self.target_path = target_path\n self.video_info = video_info\n self.__fourcc = cv2.VideoWriter_fourcc(*\"mp4v\")\n self.__writer = None\n\n def __enter__(self):\n self.__writer = cv2.VideoWriter(\n self.target_path,\n self.__fourcc,\n self.video_info.fps,\n self.video_info.resolution_wh,\n )\n return self\n\n def write_frame(self, frame: np.ndarray):\n self.__writer.write(frame)\n\n def __exit__(self, exc_type, exc_value, exc_traceback):\n self.__writer.release()\n
Get a generator that yields the frames of the video.
Parameters:
Name Type Description Default source_pathstr
The path of the video file.
required strideint
Indicates the interval at which frames are returned, skipping stride - 1 frames between each.
1
Returns:
Type Description Generator[np.ndarray, None, None]
A generator that yields the frames of the video.
Examples:
>>> import supervision as sv\n\n>>> for frame in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):\n... ...\n
Source code in supervision/utils/video.py
def get_video_frames_generator(\n source_path: str, stride: int = 1\n) -> Generator[np.ndarray, None, None]:\n\"\"\"\n Get a generator that yields the frames of the video.\n\n Args:\n source_path (str): The path of the video file.\n stride (int): Indicates the interval at which frames are returned, skipping stride - 1 frames between each.\n\n Returns:\n (Generator[np.ndarray, None, None]): A generator that yields the frames of the video.\n\n Examples:\n ```python\n >>> import supervision as sv\n\n >>> for frame in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):\n ... ...\n ```\n \"\"\"\n video = cv2.VideoCapture(source_path)\n if not video.isOpened():\n raise Exception(f\"Could not open video at {source_path}\")\n\n frame_count = 0\n success, frame = video.read()\n while success:\n if frame_count % stride == 0:\n yield frame\n success, frame = video.read()\n frame_count += 1\n\n video.release()\n
A function that takes in a numpy ndarray representation of a video frame and an int index of the frame and returns a processed numpy ndarray representation of the frame.
def process_video(\n source_path: str,\n target_path: str,\n callback: Callable[[np.ndarray, int], np.ndarray],\n) -> None:\n\"\"\"\n Process a video file by applying a callback function on each frame and saving the result to a target video file.\n\n Args:\n source_path (str): The path to the source video file.\n target_path (str): The path to the target video file.\n callback (Callable[[np.ndarray, int], np.ndarray]): A function that takes in a numpy ndarray representation of a video frame and an int index of the frame and returns a processed numpy ndarray representation of the frame.\n\n Examples:\n ```python\n >>> from supervision import process_video\n\n >>> def process_frame(scene: np.ndarray) -> np.ndarray:\n ... ...\n\n >>> process_video(\n ... source_path='source_video.mp4',\n ... target_path='target_video.mp4',\n ... callback=process_frame\n ... )\n ```\n \"\"\"\n source_video_info = VideoInfo.from_video_path(video_path=source_path)\n with VideoSink(target_path=target_path, video_info=source_video_info) as sink:\n for index, frame in enumerate(\n get_video_frames_generator(source_path=source_path)\n ):\n result_frame = callback(frame, index)\n sink.write_frame(frame=result_frame)\n
List files in a directory with specified extensions or all files if no extensions are provided.
+
+
Parameters:
+
+
+
+
Name
+
Type
+
Description
+
Default
+
+
+
+
+
directory
+
+ Union[str, Path]
+
+
+
+
The directory path as a string or Path object.
+
+
+
+ required
+
+
+
+
extensions
+
+ Optional[List[str]]
+
+
+
+
A list of file extensions to filter. Default is None, which lists all files.
+
+
+
+ None
+
+
+
+
+
+
Returns:
+
+
+
+
Type
+
Description
+
+
+
+
+
+ List[Path]
+
+
+
+
A list of Path objects for the matching files.
+
+
+
+
+
+
+
Examples:
+
>>>importsupervisionassv
+
+>>># List all files in the directory
+>>>files=sv.list_files_with_extensions(directory='my_directory')
+
+>>># List only files with '.txt' and '.md' extensions
+>>>files=sv.list_files_with_extensions(directory='my_directory',extensions=['txt','md'])
+
deflist_files_with_extensions(
+ directory:Union[str,Path],extensions:Optional[List[str]]=None
+)->List[Path]:
+"""
+ List files in a directory with specified extensions or all files if no extensions are provided.
+
+ Args:
+ directory (Union[str, Path]): The directory path as a string or Path object.
+ extensions (Optional[List[str]]): A list of file extensions to filter. Default is None, which lists all files.
+
+ Returns:
+ (List[Path]): A list of Path objects for the matching files.
+
+ Examples:
+ ```python
+ >>> import supervision as sv
+
+ >>> # List all files in the directory
+ >>> files = sv.list_files_with_extensions(directory='my_directory')
+
+ >>> # List only files with '.txt' and '.md' extensions
+ >>> files = sv.list_files_with_extensions(directory='my_directory', extensions=['txt', 'md'])
+ ```
+ """
+ directory=Path(directory)
+ files_with_extensions=[]
+
+ ifextensionsisnotNone:
+ forextinextensions:
+ files_with_extensions.extend(directory.glob(f"*.{ext}"))
+ else:
+ files_with_extensions.extend(directory.glob("*"))
+
+ returnfiles_with_extensions
+
classImageSink:
+ def__init__(
+ self,
+ target_dir_path:str,
+ overwrite:bool=False,
+ image_name_pattern:str="image_{:05d}.png",
+ ):
+"""
+ Initialize a context manager for saving images.
+
+ Args:
+ target_dir_path (str): The target directory where images will be saved.
+ overwrite (bool, optional): Whether to overwrite the existing directory. Defaults to False.
+ image_name_pattern (str, optional): The image file name pattern. Defaults to "image_{:05d}.png".
+
+ Examples:
+ ```python
+ >>> import supervision as sv
+
+ >>> with sv.ImageSink(target_dir_path='target/directory/path', overwrite=True) as sink:
+ ... for image in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):
+ ... sink.save_image(image=image)
+ ```
+ """
+ self.target_dir_path=target_dir_path
+ self.overwrite=overwrite
+ self.image_name_pattern=image_name_pattern
+ self.image_count=0
+
+ def__enter__(self):
+ ifos.path.exists(self.target_dir_path):
+ ifself.overwrite:
+ shutil.rmtree(self.target_dir_path)
+ os.makedirs(self.target_dir_path)
+ else:
+ os.makedirs(self.target_dir_path)
+
+ returnself
+
+ defsave_image(self,image:np.ndarray,image_name:Optional[str]=None):
+"""
+ Save a given image in the target directory.
+
+ Args:
+ image (np.ndarray): The image to be saved.
+ image_name (str, optional): The name to use for the saved image. If not provided, a name will be generated using the `image_name_pattern`.
+ """
+ ifimage_nameisNone:
+ image_name=self.image_name_pattern.format(self.image_count)
+
+ image_path=os.path.join(self.target_dir_path,image_name)
+ cv2.imwrite(image_path,image)
+ self.image_count+=1
+
+ def__exit__(self,exc_type,exc_value,exc_traceback):
+ pass
+
defsave_image(self,image:np.ndarray,image_name:Optional[str]=None):
+"""
+ Save a given image in the target directory.
+
+ Args:
+ image (np.ndarray): The image to be saved.
+ image_name (str, optional): The name to use for the saved image. If not provided, a name will be generated using the `image_name_pattern`.
+ """
+ ifimage_nameisNone:
+ image_name=self.image_name_pattern.format(self.image_count)
+
+ image_path=os.path.join(self.target_dir_path,image_name)
+ cv2.imwrite(image_path,image)
+ self.image_count+=1
+
defcrop(image:np.ndarray,xyxy:np.ndarray)->np.ndarray:
+"""
+ Crops the given image based on the given bounding box.
+
+ Args:
+ image (np.ndarray): The image to be cropped, represented as a numpy array.
+ xyxy (np.ndarray): A numpy array containing the bounding box coordinates in the format (x1, y1, x2, y2).
+
+ Returns:
+ (np.ndarray): The cropped image as a numpy array.
+
+ Examples:
+ ```python
+ >>> import supervision as sv
+
+ >>> detection = sv.Detections(...)
+ >>> with sv.ImageSink(target_dir_path='target/directory/path') as sink:
+ ... for xyxy in detection.xyxy:
+ ... cropped_image = sv.crop(image=image, xyxy=xyxy)
+ ... sink.save_image(image=image)
+ ```
+ """
+
+ xyxy=np.round(xyxy).astype(int)
+ x1,y1,x2,y2=xyxy
+ cropped_img=image[y1:y2,x1:x2]
+ returncropped_img
+
defplot_images_grid(
+ images:List[np.ndarray],
+ grid_size:Tuple[int,int],
+ titles:Optional[List[str]]=None,
+ size:Tuple[int,int]=(12,12),
+ cmap:Optional[str]="gray",
+)->None:
+"""
+ Plots images in a grid using matplotlib.
+
+ Args:
+ images (List[np.ndarray]): A list of images as numpy arrays.
+ grid_size (Tuple[int, int]): A tuple specifying the number of rows and columns for the grid.
+ titles (Optional[List[str]]): A list of titles for each image. Defaults to None.
+ size (Tuple[int, int]): A tuple specifying the width and height of the entire plot in inches.
+ cmap (str): the colormap to use for single channel images.
+
+ Raises:
+ ValueError: If the number of images exceeds the grid size.
+
+ Examples:
+ ```python
+ >>> import cv2
+ >>> import supervision as sv
+
+ >>> image1 = cv2.imread("path/to/image1.jpg")
+ >>> image2 = cv2.imread("path/to/image2.jpg")
+ >>> image3 = cv2.imread("path/to/image3.jpg")
+
+ >>> images = [image1, image2, image3]
+ >>> titles = ["Image 1", "Image 2", "Image 3"]
+
+ %matplotlib inline
+ >>> plot_images_grid(images, grid_size=(2, 2), titles=titles, size=(16, 16))
+ ```
+ """
+ nrows,ncols=grid_size
+
+ iflen(images)>nrows*ncols:
+ raiseValueError(
+ "The number of images exceeds the grid size. Please increase the grid size or reduce the number of images."
+ )
+
+ fig,axes=plt.subplots(nrows=nrows,ncols=ncols,figsize=size)
+
+ foridx,axinenumerate(axes.flat):
+ ifidx<len(images):
+ ifimages[idx].ndim==2:
+ ax.imshow(images[idx],cmap=cmap)
+ else:
+ ax.imshow(cv2.cvtColor(images[idx],cv2.COLOR_BGR2RGB))
+
+ iftitlesisnotNoneandidx<len(titles):
+ ax.set_title(titles[idx])
+
+ ax.axis("off")
+ plt.show()
+
@dataclass
+classVideoInfo:
+"""
+ A class to store video information, including width, height, fps and total number of frames.
+
+ Attributes:
+ width (int): width of the video in pixels
+ height (int): height of the video in pixels
+ fps (int): frames per second of the video
+ total_frames (int, optional): total number of frames in the video, default is None
+
+ Examples:
+ ```python
+ >>> import supervision as sv
+
+ >>> video_info = sv.VideoInfo.from_video_path(video_path='video.mp4')
+
+ >>> video_info
+ VideoInfo(width=3840, height=2160, fps=25, total_frames=538)
+
+ >>> video_info.resolution_wh
+ (3840, 2160)
+ ```
+ """
+
+ width:int
+ height:int
+ fps:int
+ total_frames:Optional[int]=None
+
+ @classmethod
+ deffrom_video_path(cls,video_path:str)->VideoInfo:
+ video=cv2.VideoCapture(video_path)
+ ifnotvideo.isOpened():
+ raiseException(f"Could not open video at {video_path}")
+
+ width=int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height=int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps=int(video.get(cv2.CAP_PROP_FPS))
+ total_frames=int(video.get(cv2.CAP_PROP_FRAME_COUNT))
+ video.release()
+ returnVideoInfo(width,height,fps,total_frames)
+
+ @property
+ defresolution_wh(self)->Tuple[int,int]:
+ returnself.width,self.height
+
defget_video_frames_generator(
+ source_path:str,stride:int=1
+)->Generator[np.ndarray,None,None]:
+"""
+ Get a generator that yields the frames of the video.
+
+ Args:
+ source_path (str): The path of the video file.
+ stride (int): Indicates the interval at which frames are returned, skipping stride - 1 frames between each.
+
+ Returns:
+ (Generator[np.ndarray, None, None]): A generator that yields the frames of the video.
+
+ Examples:
+ ```python
+ >>> import supervision as sv
+
+ >>> for frame in sv.get_video_frames_generator(source_path='source_video.mp4', stride=2):
+ ... ...
+ ```
+ """
+ video=cv2.VideoCapture(source_path)
+ ifnotvideo.isOpened():
+ raiseException(f"Could not open video at {source_path}")
+
+ frame_count=0
+ success,frame=video.read()
+ whilesuccess:
+ ifframe_count%stride==0:
+ yieldframe
+ success,frame=video.read()
+ frame_count+=1
+
+ video.release()
+
Process a video file by applying a callback function on each frame and saving the result to a target video file.
+
+
Parameters:
+
+
+
+
Name
+
Type
+
Description
+
Default
+
+
+
+
+
source_path
+
+ str
+
+
+
+
The path to the source video file.
+
+
+
+ required
+
+
+
+
target_path
+
+ str
+
+
+
+
The path to the target video file.
+
+
+
+ required
+
+
+
+
callback
+
+ Callable[[np.ndarray, int], np.ndarray]
+
+
+
+
A function that takes in a numpy ndarray representation of a video frame and an int index of the frame and returns a processed numpy ndarray representation of the frame.
defprocess_video(
+ source_path:str,
+ target_path:str,
+ callback:Callable[[np.ndarray,int],np.ndarray],
+)->None:
+"""
+ Process a video file by applying a callback function on each frame and saving the result to a target video file.
+
+ Args:
+ source_path (str): The path to the source video file.
+ target_path (str): The path to the target video file.
+ callback (Callable[[np.ndarray, int], np.ndarray]): A function that takes in a numpy ndarray representation of a video frame and an int index of the frame and returns a processed numpy ndarray representation of the frame.
+
+ Examples:
+ ```python
+ >>> from supervision import process_video
+
+ >>> def process_frame(scene: np.ndarray) -> np.ndarray:
+ ... ...
+
+ >>> process_video(
+ ... source_path='source_video.mp4',
+ ... target_path='target_video.mp4',
+ ... callback=process_frame
+ ... )
+ ```
+ """
+ source_video_info=VideoInfo.from_video_path(video_path=source_path)
+ withVideoSink(target_path=target_path,video_info=source_video_info)assink:
+ forindex,frameinenumerate(
+ get_video_frames_generator(source_path=source_path)
+ ):
+ result_frame=callback(frame,index)
+ sink.write_frame(frame=result_frame)
+
 +
+